计量经济学 | Stata的应用

计量经济学 | Stata的应用
Prong前言
计量经济学对生活中的经济现象进行研究,试图找到现象的因果关系。正如我在[概况]所说,计量经济学的研究过程可以总结为下面这些步骤:
- 明确研究问题
- 写出要估计的回归方程式
- 选择适当的数据集
- 使用统计软件,用数据估计回归方程式
- 分析并解释结果
常用于计量经济学的软件有Eviews、Matlab、Stata等。由于我的科研训练涉及面板数据的分析,所以选用Stata作为研究的主力软件。本篇文章根据我的科研进度持续更新。
研究问题和主要思路
探索生育率和房价之间的关系。
数据选取和整理
为了探索生育率和房价之间的关系,我们选用2002至2021的各项有关数据:
- 被解释变量
- 生育率
- 解释变量
- 平均房价
- 控制变量
- 人均GDP
数据来源分为两部分:
- 2014年以前各项数据在《中国区域经济统计年鉴》中可以直接找到。
- 2014年以后从各省《XX省统计年鉴》中获取数据。
从各《统计年鉴》中获得的数据是截面数据,而且往往由于表格的设置,我们首先得到的是一个地区对应一个或几个变量,选取的变量需要进行整理,从而形成对应年份完整的截面数据。得到截面数据之后,需要转化为面板数据才能在Stata中进行回归分析。
数据来源一定要选取可靠的官方平台,可以避免无数潜在的bug
下载统计年鉴的数据
统计年鉴通常由各级统计局进行整理,在次年发布上一年的有关数据。例如:《2014中国区域经济统计年鉴》
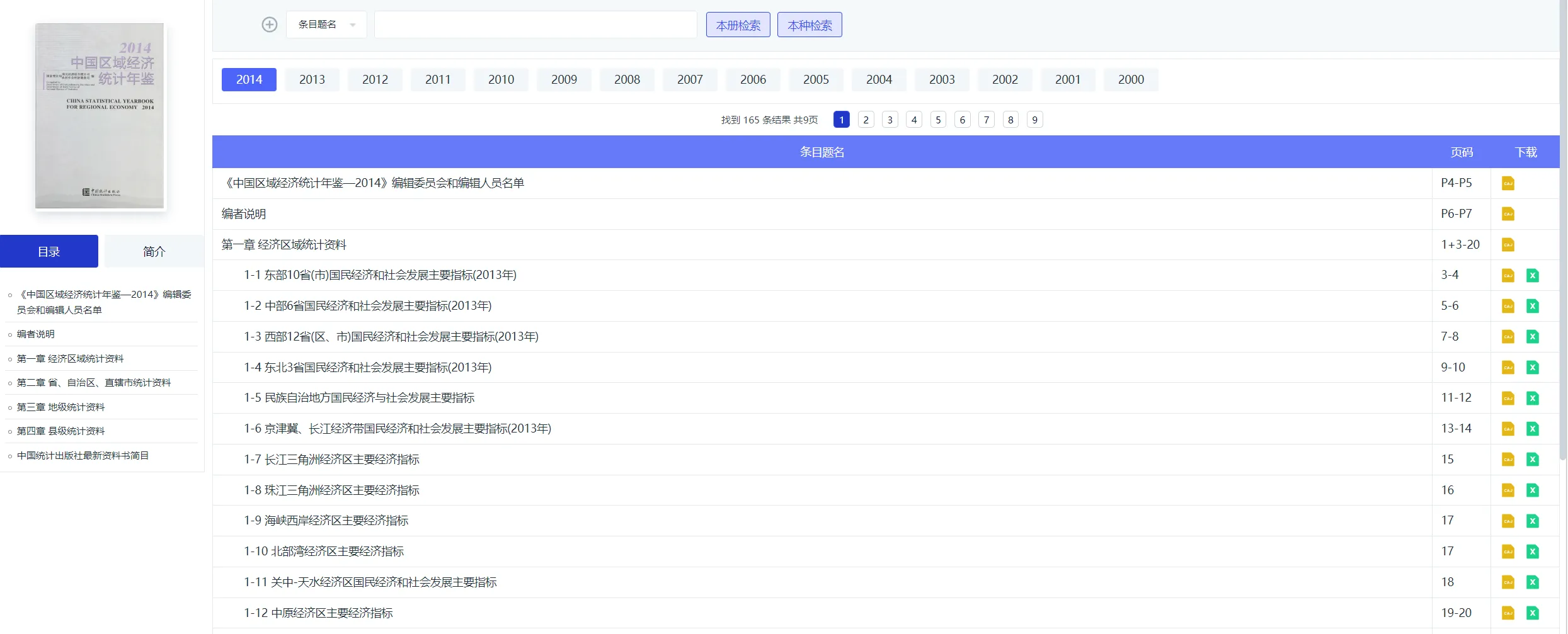
登录知网中国经济社会大数据研究平台,选择《区域经济统计年鉴》
选择对应年度,例如我们需要查看2012年的数据,那么就需要打开2013年的统计年鉴。
由于我们需要的是各地州的相关数据,在左侧目录选择 第三章 地级统计资料 ,以地区生产总值为例:
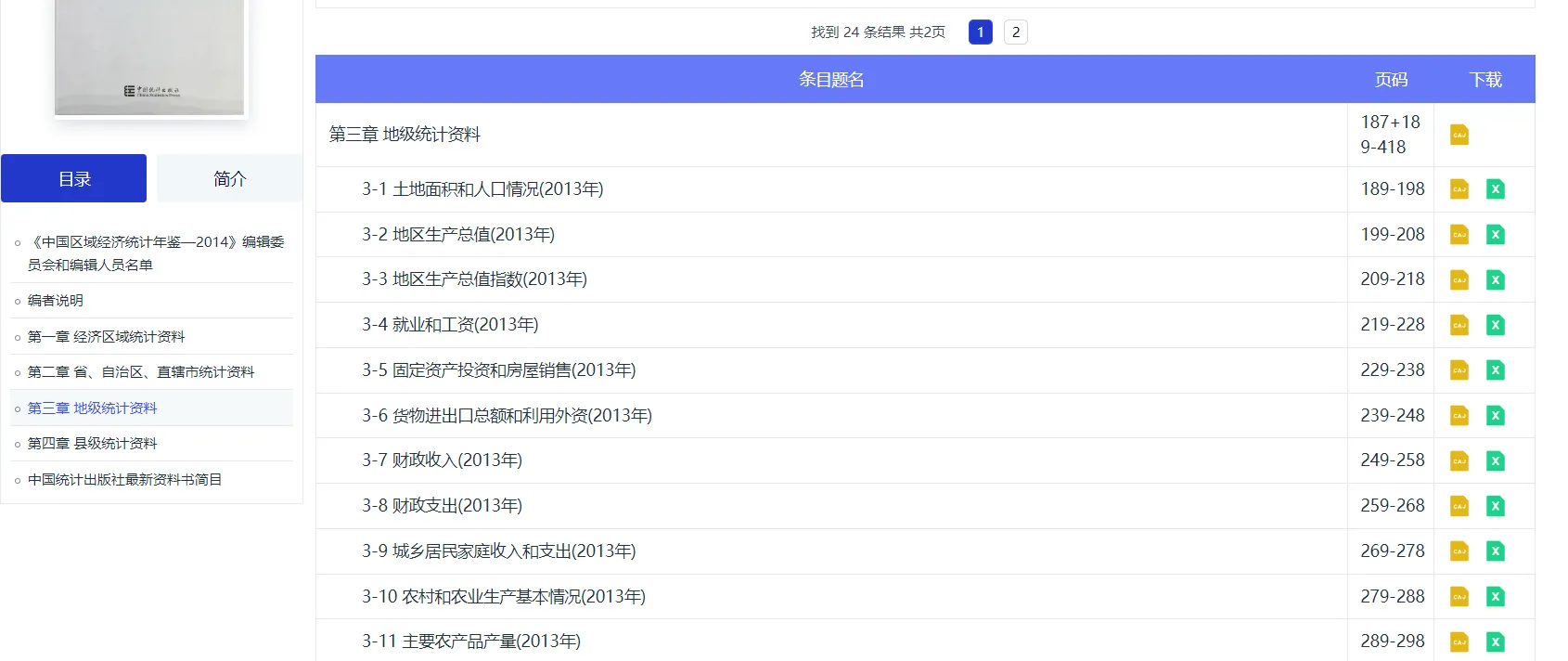
选择对应的表格,下载excel版本,建议在下载数据的时候就做好整理,比如按年份分类收集。
需要注意,一是:
不同年份的统计年鉴表格的分录可能有所区别。例如商品房销售面积和商品房销售总额,在2013的统计年鉴是《3-5 固定资产投资和房屋销售》,而在2002年的统计年鉴则是《固定资产投资》。
二是:
不同年份的统计单位可能不同。例如出生人口在2002年的单位是 人,而在2008年的单位变为了 万人。
三是:
不同年份,各省行政区划可能会发生变化。以我在整理中发现的情况为例:
2003年起广西省南宁地区改为崇左市
2003年起,云南省昭通地区改为昭通市,丽江地区改为丽江市,临沧地区改为临沧市,思茅地区改为思茅市
2006年起重庆市新增江津区、合川区、永川区、南川区
2010年起湖北省襄樊市改为襄阳市
2011年起,贵州省铜仁地区改为铜仁市,毕节地区改为毕节市
2011年起安徽省撤销巢湖市
将我们所需要的全部年份的相应表格下载并做好整理,记录下中途可能遇到的诸如单位转换、区划变动等问题,然后就可以进行下一步的操作。
整理为截面数据
由于实证分析需要使用面板数据,我们需要把原始表格转化为面板数据。我目前还不清楚高效的转化方法,所以使用excel一步一步手动整理,思路如下:
- 确定所需变量
- 将某一年份的相关变量(地名、GDP、总人口、出生人口等)从原始表格复制到一张新表里,形成截面数据
- 把不同年份的截面数据合并成面板数据
可能会遇到的问题和初步解决思路
- 区划变动导致地名前后不一
- 建立一个地名对照表,检查不同年份区划的变化,更改名字则以最新地名为准,新增区划则在前面年份留空,撤销区划则在后面年份留空,合并区划同样在后续年份留空。
- 计量单位前后不一
- 手动统一,选取方便的计量单位
- 没有删除标题栏(上面也有标题栏,下面也有标题栏)
- 用
筛选选出来然后删除
- 用
- 历史原因某些观测量缺失
- 因为由观测值有缺失,面板数据在Stata中作为不平衡面板数据进行处理
- 错别字
- 例如我在复制之后
贵州省就变成了责州省,我也不知道怎么搞出来这个问题的。 - 用
查找替换干了它
- 例如我在复制之后
- 数据包含空格
- 用
查找替换干了它
- 用
- 数据小数点
.变成'- 一眼丁真,用筛选
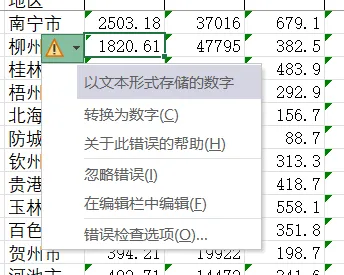
- 数据被excel储存为文本型

- 一方面建议复制粘贴时,使用
选择性粘贴-粘贴为值 - 另一方面而言,强烈建议团队统一用Microsoft Excel对数据进行处理,不要WPS和Excel混用,不然可能出现一些玄学的bug
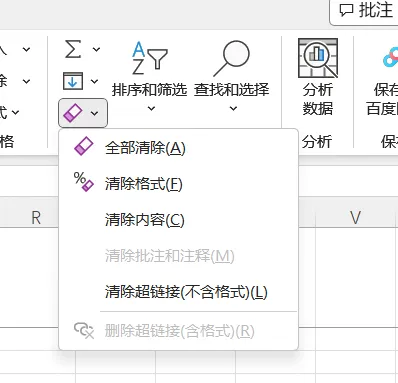
- 有几种方法处理:
- 点击
转换为数字 - 清除格式
- 点击
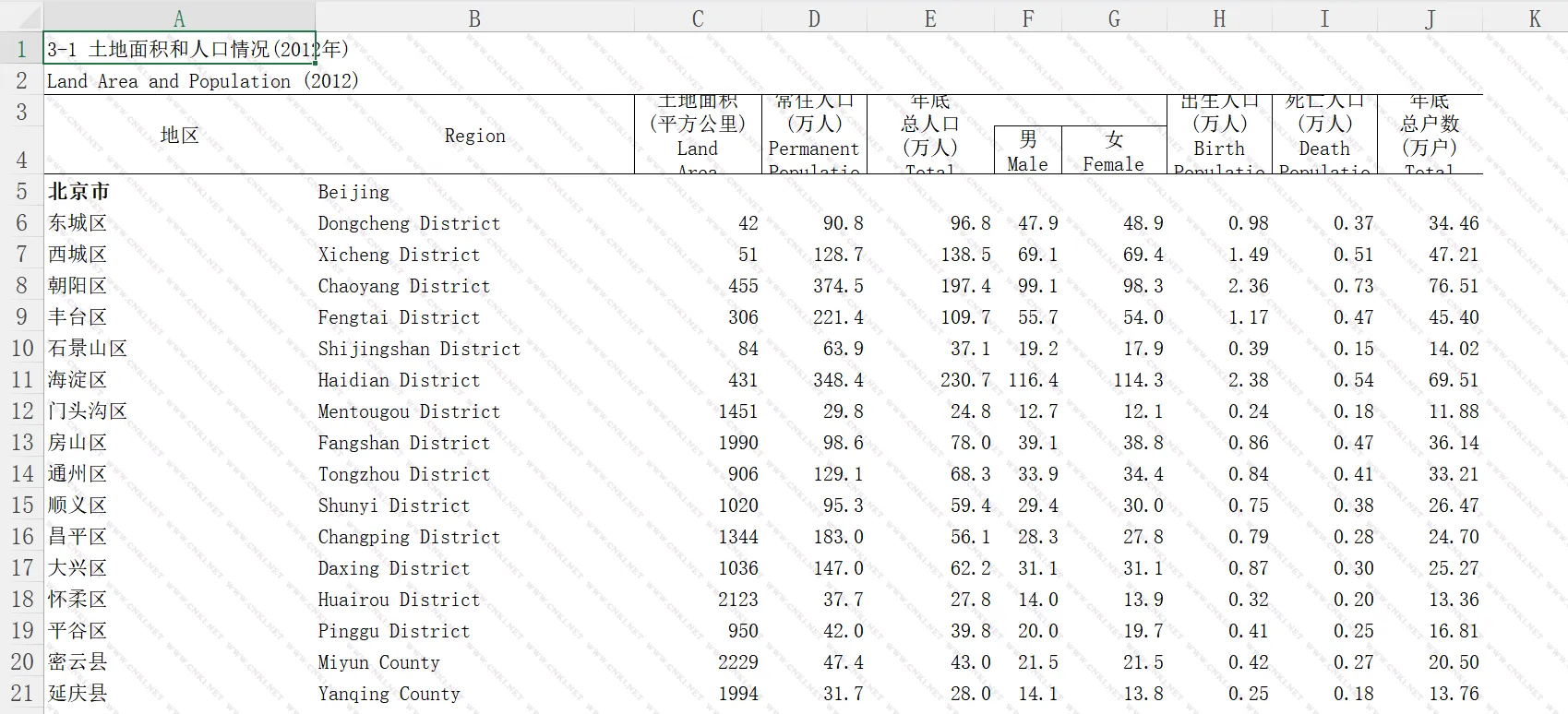
初步整理
下载好统计年鉴的excel数据之后,还需要对它进行初步整理。包含我们需要的数据对应的excel表格如下:

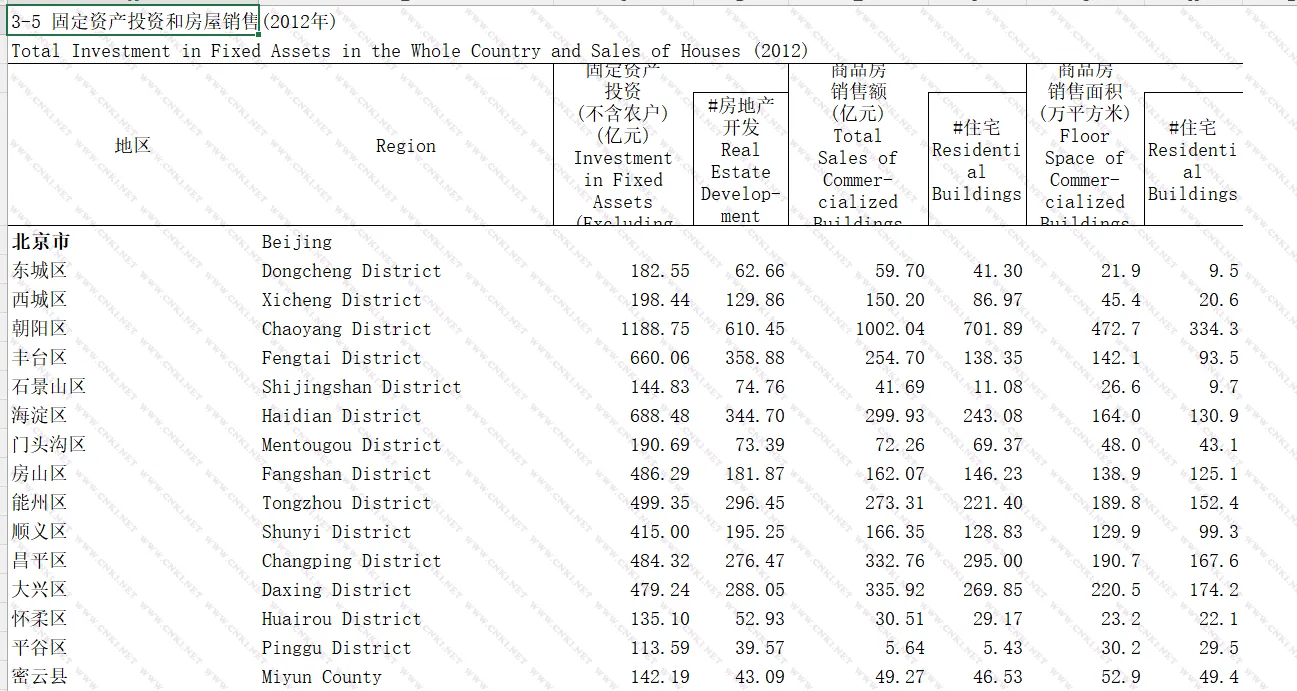
选中我们需要的地名和变量到一张新表里(地名是为了方便前后对照以防出错),核对完成后地名保留一列,删除其余重复的地名列即可。这样我们就得到了一份初步的截面数据。
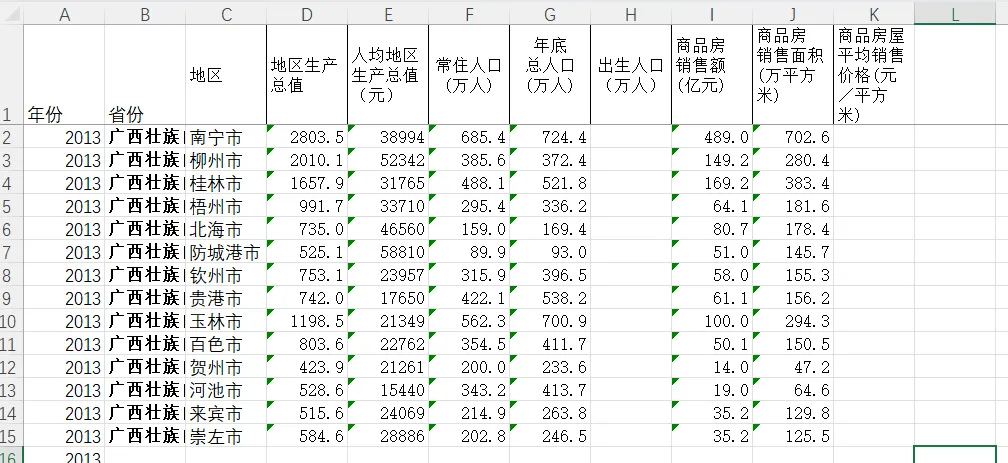
如你所见,我使用的变量有平均房价、出生率,这样的变量在统计年鉴没有直接给出,而是需要我们计算得到。我的建议是:
- 复制数据从本地文件复制,不要从在线预览的文件里复制。
- 在截面数据这里保留需要用于后续计算的原始数据,以便后续的数据处理。
- 需要计算的变量统一在面板数据的草稿里运算,因为我们的面板数据势必是检查过变量前后一致性的,可以保证变量、区划名称一致,从而便于我们获取所需要构造的新变量。
我们现在已经得到了在同一年份内准确的截面数据,但是如前文所言,可能会存在区划变动、地名变更的问题。建议制作一份不同年份地名对照表,并按前文的解决思路订正、统一地名,记录变动情况。

地名的检查完成以后,还要对计量单位进行检查、统一。通过这样的处理方法,我们就保证了地名的一致性、变量的一致性。将各个年份的截面数据以数据年份命名,保存至一个新工作簿中。

如果前后地名不统一,对于系统来说数据就贼不平衡,有的缺早期数据,有的没有晚期数据,非常不利于我们的回归分析。
而变量如果不统一,例如前面用粗出生率,后面用,总人口和常住人口的巨大差异就放大了数据的波动性和不准确性。因此建议使用在绝大多数年份都可以得到的统计量,便于后续分析。
整理为面板数据
问题和解决思路
现在假设通过前面得到的面板数据,已经统一前后地名、确定计量单位无误、不包含因为excel数据操作得到的提示符(比如说#DIV/0!、#VALUE!)、不存在数据里因为包含空格、引号导致的数据无效。
具体处理
excel有快捷方法把每个工作表的内容合并到一张新工作表,此处不再赘述。也可以一张表一张表慢慢复制。总之经过合并以后,我们就得到了我们的面板数据的草稿
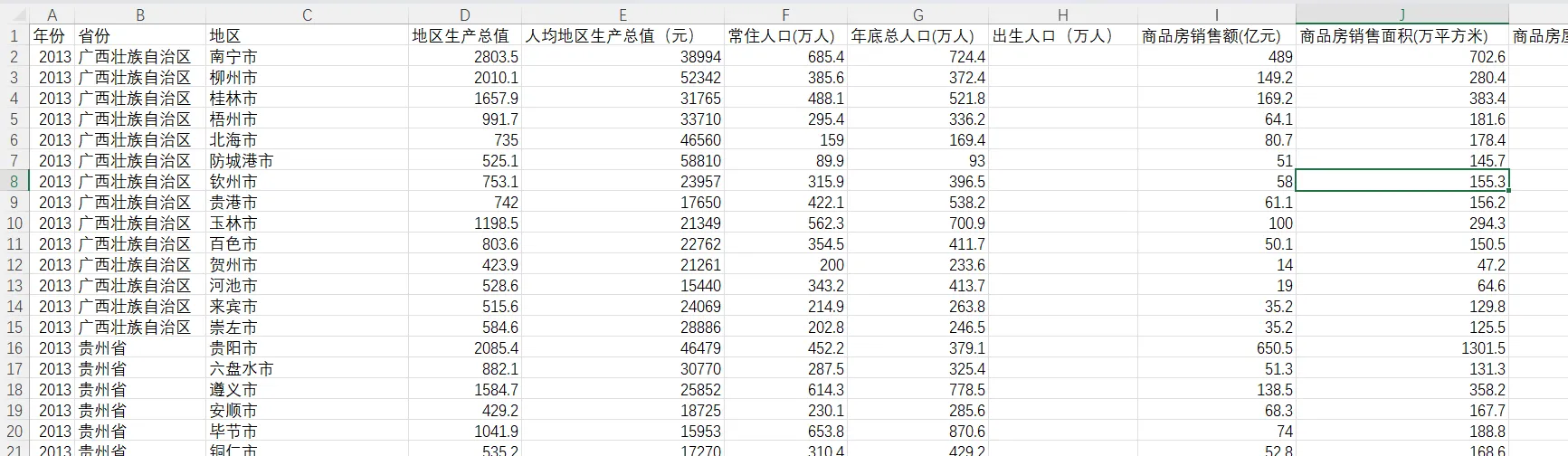
这样的表格往往是不能直接在stata里方便的使用的。在Stata早先的版本中,中文变量名称会无法显示或显示会乱码,尽管在新版本(例如stata 17)中已经支持中文的显示,我还是建议用字母缩写来重命名变量,减少出bug的几率,也方便写代码的时候输入变量名。
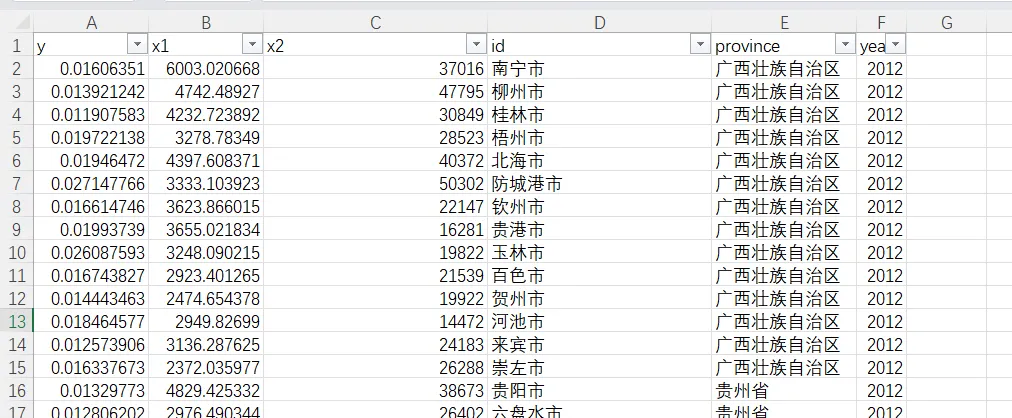
对数据进行整理,可以在stata里输指令,也可以在excel用笨办法处理。此处记录stata的处理方法(因为以前我不会,防止以后忘记)
1 | /*导入excel数据表,把第一行作为变量名*/ |
经过这样的操作,我们就得到了stata需要的的面板数据形式。
数据的实证分析
实证分析的步骤其实有规可循:
- 描述性统计
- 相关性分析
- 共线性判断
描述性统计
首先进行的是描述性统计。描述性统计分析主要是对研究样本中与所有变量相关的数据进行统计描述,包括频数分析、中心趋势分析、方差分析、分布分析这类十分基本的统计图形。基本思路如下
- 使用
tabulate或tabstat或summary命令生成表格。 - 使用
scatter或twoway命令绘制散点图。 - 使用
lfitci制作拟合线和置信区间。 - 在上述命令后加上
by (分组依据)进行分组。 - 使用
logout输出结果并保存。
在这部分,我们需要对原始数据进行描述性统计,通过制作含有原始数据的样本量、中位数、标准差、最小值、最大值的统计表格,绘制被解释变量与不同解释变量的分布情况以及对应的拟合线、置信区间的散点图。对原始数据进行基本分析,从而决定接下来的处理方法。然后我们可以按年份分组、按地区分组继续制作这样的表格、散点图,进一步进行分析。
描述性统计表格
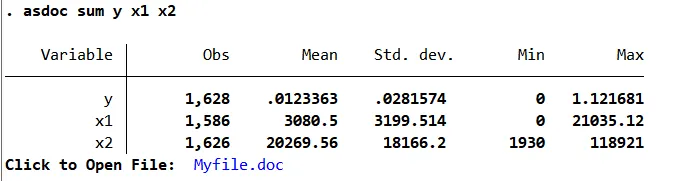
首先,对原始数据进行基本的描述性统计表格。

可以看出我们收集1483个有效的数据样本,由于部分有缺失,x1平均房价有1442个样本,x2人均GDP有1442个样本。制作这样的基本描述统计表格,可以用以下三个方法。
- 方法一
利用tabstat制作表格,logout输出。
logout,save(基本统计描述)word replace:tabstat y x1 x2,s(N mean p50 sd min max) f(%12.3f) c(s)
这个语句有两个部分,第一部分logout是输出语法,可以设定输出文件的名字,可以选输出为word、excel等类型。
第二部分是tabstat统计表语法,语法是tabstat [被解释变量] [解释变量], s() f() c() - 方法二
使用summary - 方法三
安装asdoc
ssc install asdoc
然后,可以根据年份分组得到进一步的统计结果描述,例如:
logout,save(按年份分组统计描述)word replace:tabstat logy logx1 logx2, by(year) /*按年份分组统计变量的均值、标准差等*/
散点图绘制
散点图的绘制主要使用scatter语法,拟合线和置信区间的绘制主要使用lfitci语法。而如果需要同时绘制散点图、拟合线、置信区间,可以使用graph twoway的语法。
scatter logy logx1 || lfit logy logx1 /*出生率与房价的散点图,logout,save(出生率与房价的散点图)word replace:*/
scatter logy logx2 || lfit logy logx2 /*出生率与人均GDP的散点图,logout,save(出生率与人均GDP的散点图)word replace:*/
graph twoway (scatter logy logx1) (lfitci logy logx1), by(year) /*绘制出生率和房价的散点图,并加入拟合线和置信区间,按年份分组,logout,save(带拟合线和置信区间分年度的出生率和房价散点图)word replace:*/
相关分析
接下来,我们需要进行相关分析,判断各变量之间的相关性。这一部分主要使用连玉君老师制作的pwcorr_a相关分析统计表。与自带的相关分析pwcorr相比,pwcorr_a能用*的数目显示出置信度,例如*代表0.001,**代表0.025,***代表0.05。语法是pwcorr_a [被解释变量] [解释变量]
logout,save(相关分析)word replace:pwcorr_a y x1 x2
回归分析
当我们做完描述性统计和相关分析,接下来可以进行回归分析。基本思路是使用OLS、双向固定效应、系统GMM回归进行基准回归分析。
OLS回归,语法是regress [被解释变量] [解释变量]
regress logy logx1 logx2
整理数据
sort id year
对面板数据进行双向固定效应回归(个体效应(id)、时间效应(year)),主要使用xtreg,基本语法是xtreg [被解释变量] [解释变量], fe。在后续我们还会在此基础上检验地区效应、房价水平效应。
xtreg logy logx1 logx2, fe
对面板数据进行系统GMM回归,通常使用xtabond2。它的一般形式是xtabond2 depvar indepvars, gmm(gmmvars) iv(ivvars) options,其中depvar是因变量,indepvars是自变量,gmmvars是用于GMM估计的内生变量,ivvars是用于IV估计的外生变量,options是一些可选项。
方式一xtabond2 logy L.logy L.logx1 L.logx2, gmm(L.logy L.logx1 L.logx2) iv(L.logy L.logx1 L.logx2) robust /*系统GMM回归*/
或者使用方式二xtabond2 logy l.logy logx1 logx2, gmm(l.logy) iv(logx1 logx2) robust关键是区分外生内生变量。
方式一将所有的滞后量都视为内生变量,并且使用它们的滞后水平作为工具变量;方式二将因变量的滞后量视为内生变量,并且使用它的滞后水平作为工具变量,而将解释变量和它们的滞后量视为外生变量,并且使用它们的当期值作为工具变量。
如果认为所有的滞后量都与当期误差项相关,那么方式一可能更合理;如果认为解释变量和它们的滞后量与当期误差项无关,那么方式二可能更合理。这取决于您对模型动态性和数据特征的假设和检验。
在xtabond2命令中加入twostep选项,以便进行两步估计,并且使用Windmeijer (2005) 的有限样本校正来计算稳健标准误。例如:
xtabond2 logy L.logy L.logx1 L.logx2, gmm(L.logy L.logx1 L.logx2) iv(L.logy L.logx1 L.logx2) twostep robust
或者
xtabond2 logy l.logy logx1 logx2, gmm(l.logy) iv(logx1 logx2) twostep robust
异质性分析
稳健性分析
/将数据对数化,消除异方差/
gen logy = log(y)
gen logx1 = log(x1)
gen logx2 = log(x2)
/对基本事实使用表格和散点图描述/
logout,save(基本统计描述)word replace:tabstat y x1 x2,s(N mean p50 sd min max) f(%12.3f) c(s) /做基本统计描述然后输出/
logout,save(对数化后基本统计描述)word replace:tabstat logy logx1 logx2,s(N mean p50 sd min max) f(%12.3f) c(s) /做基本统计描述然后输出/
logout,save(按年份分组统计描述)word replace:tabstat logy logx1 logx2, by(year) /按年份分组统计变量的均值、标准差等/
scatter logy logx1 || lfit logy logx1 /出生率与房价的散点图,logout,save(出生率与房价的散点图)word replace:/
scatter logy logx2 || lfit logy logx2 /出生率与人均GDP的散点图,logout,save(出生率与人均GDP的散点图)word replace:/
graph twoway (scatter logy logx1) (lfitci logy logx1), by(year) /绘制出生率和房价的散点图,并加入拟合线和置信区间,按年份分组,logout,save(带拟合线和置信区间分年度的出生率和房价散点图)word replace:/
/做相关分析/
logout,save(相关分析)word replace:pwcorr_a logy logx1 logx2
logout,save(对数化后相关分析)word replace:pwcorr_a logy logx1 logx2
/使用OLS、双向固定效应、系统GMM回归进行基准回归分析/
regress logy logx1 logx2 /OLS回归/
sort id year /整理数据/
xtset id year /设置面板数据结构/
/个体效应和随机效应的联合显著性检验/
xtreg logy logx1 logx2, fe //fe表示固定效应,p<0.01个体效应显著;若同时包括时期虚拟变量,xtreg invest mvalue kstock i.year,fe,利用 testparm 检验
xtreg logy logx1 logx2, re //re表示随机效应
xttest0 //检验随机效应是否显著,需要运行随机效应模型后使用
/hausman检验/
xtreg logy logx1 logx2 , fe /固定效应模型/
est store fe /保存回归结果/
xtreg logy logx1 logx2 , re /随机效应模型/
est store re /保存回归结果/
hausman fe re /比较两者结果,小于零选用固定效应/
/当模型误差项存在序列相关或异方差时,用异方差和序列相关检验/
xtserial logy logx1 logx2 /序列相关检验/
xtreg logy logx1 logx2, fe
xttest3 //异方差检验
xtreg logy logx1 logx2, fe /双向固定效应回归/
xtabond2 logy L.logy L.logx1 L.logx2, gmm(L.logy L.logx1 L.logx2) iv(L.logy L.logx1 L.logx2) robust /系统GMM回归/
//或者这样?xtabond2 logy l.logy logx1 logx2, gmm(l.logy) iv(logx1 logx2) robust
/以不同地区、不同房价绝对水平与房价增长率进行异质性分析/
by id: egen x1_mean = mean(x1) /计算每个地区的平均房价水平/
/以不同房价绝对水平进行异质性分析/
xtile hp = x1, nq(4) /将房价划分为四个等频组别,并生成新变量hp表示组别编号/
sort hp id year /整理数据/
by hp: regress y x1 x2
/以不同房价增长率进行异质性分析/
sort id year
bysort id: gen dx1 = D.x1 /计算每个地区的房价增长率/
egen dx1_mean = mean(dx1) /计算每个地区的平均房价增长率/
xtile hg = dx1_mean, nq(4) /将房价增长率划分为四个等频组别,并生成新变量hg表示组别编号/
sort hg id year /整理数据/
by hg: regress y x1 x2
xtreg y x1 x2 i.id, fe /在双向固定效应回归中加入地区虚拟变量,检验地区效应/
xtreg y x1 x2, fe /i.id是固定地区效应,而fe是个体固定效应,相对于更精确的固定地区效应/
xtreg y x1_mean x2 i.year, fe /在双向固定效应回归中用平均房价水平替代房价,检验房价水平效应/
xtreg y dx1 x2 i.year, fe /在双向固定效应回归中用房价增长率替代房价,检验房价增长率效应/
改进
- 11月1日前初稿
- 作者顺序
现行代码
1 | /*将数据对数化,消除异方差*/ |
附录
常用数据平台
中国区域经济统计年鉴
云南省统计年鉴
贵州省统计年鉴
广西省统计年鉴
江西省统计年鉴
江苏省统计年鉴
浙江省统计年鉴
上海市统计年鉴
四川省统计年鉴
重庆市统计年鉴
湖北省统计年鉴
安徽省统计年鉴