计量经济学 | 时间序列数据

计量经济学 | 时间序列数据
Prong针对大多数教材对计量经济学尤其是金融计量学的知识讲解要么过于繁琐、要么过于简单的问题,我亲手撰写了这份讲义,按平稳性检验、白噪声检验、条件异方差模型的大纲,把时间序列数据完整梳理清楚,建立了计量经济学从静态模型到动态模型的相关知识的讲解。目前仍在继续更新中。
南京理工大学,张茂源, 写于2023-12-22
[toc]
主要分析思路
时间序列的分析,就围绕自相关性展开。一是对序列做平稳性检验,二是对残差做白噪声检验。将被解释变量的变动不断拆分为“确定”+“随机”两部分,用自相关预测确定,白噪声描述随机。
计量经济学 把生活中的某个问题抽象化变为数学模型,试图利用数学模型进行分析、预测。我们希望预测的是 被解释变量 ,由于它尚未发生,因此存在不确定性。我们需要找出 解释变量 作为 发生变动的原因,用 的变动来解释 被解释变量 的变动,所以可以用 得到的估计值。学习计量经济学时,我们从静态模型(模型只包含当前时间点的变量,没有未来或是历史数据)开始,建立
假如是一元线性回归,解释变量只有,被解释变量是,那么就相当于构建了一个二元一次函数,这是一条直线,直线上的点就是对应的估计值,我们至少需要两个点才能做出这条一次函数的图像,选取的样本点越多,对真实拟合就越高。
然而,生活中的真实情况不会这么完美地正好和我们预测的直线上的点重合,我们需要预测的未来值是不确定的、可能和完美的估计值存在偏差的,也就是说 是存在波动的可4能的。因此我们建立的线性回归模型中的“原因”包含了两个部分:
-
一个是可观测到的解释变量的线性组合;
-
另一个是不可观测的随机误差项 来表示这种随机的波动、误差。
我们可以根据已经观测到的变量的历史值,试图最小化残差平方和,用多元函数求极值的方式,令对各个参数的偏导等于零,列出方程组并求解,从而得到估计的解释变量的系数值。这样一来,只要能够知道需要预测的被解释的对应的解释变量的取值,就可以用解释变量的线性组合得到一个理想化的估计的。解释变量可以由观测得到,那么一旦估计出了系数值,就可以把观测到的解释变量带入样本回归方程得到回归直线上的估计值: 。生活中的现象不可能是这样一条完全笔直的直线,由于各种难以观察的影响的存在,实际上要引入随机误差项 ,描述真实状况对理想状态的偏离来表示各自难以观察的因素。而在我们选取的样本中,可以用真实值对拟合值的偏离,也就是残差来作为随机误差的估计。
这样一来,被预测的对象理想化的估计值,再加上理想化地预测的随机误差的估计值,那么模型中结果发生的原因中,可观测和不可观测部分都被我们纳入考虑,并且得到准确的估计,所以就能够在很大程度上把理想化的估计值 变得更加准确,能正确反映出的真实情况。
上面三个式子,是计量经济学研究的数据的类型,分别是:
- 时间序列数据:同一个个体在不同时间点的统一项数据组成的序列,例如:某同学过去10次考试的历次得分情况组成的分数序列、某一只股票多年的价格序列,我们称之为 时间序列数据;
- 截面数据:同一时点的多个个体的多项数据,例如:某次考试全班50人每人语文、数学、英语三门学科的各科分数;
- 面板数据:多个个体的多维度的时间序列数据:例如:全班40人10次考试每人每科的各自得分。例如某十只股票多年的价格 和各个影响因素, 是不同时点, 是不同个体。
金融计量学重点研究的是其中的时间序列数据。静态模型我们认为所有的解释变量都来自于外部,并且都是针对当下的数据进行讨论,解释变量对被解释变量的解释作用只发生在当下,不会影响到未来。
时间序列数据中,因为数据一般具有自相关性,所以我们试图把自身的历史值也作为解释变量,纳入模型,也就是认为解释变量的解释作用的作用时间不止在当下,而是可以有持续性,或者说被解释变量对解释变量的起到的影响是有记忆的,就像人对一件事情是有记忆的,不会发生了就马上忘记,随时间的推移慢慢淡忘,深刻程度在时间上有近大远小的特点。因此,时间序列数据实际上拓宽了解释变量的来源(可能是历史的自己,也可能是历史的自己的预测误差,取决于时间序列的自相关性是如何体现的)。所以,确定序列的自相关性,决定了我们应该选择什么样的解释变量,从而让时间序列的预测更加准确。
静态模型中,如果参数估计值是线性、无偏、最小方差、甚至一致的,同时残差是零均值、同方差、无自相关的白噪声,那么对被解释变量 的拟合是准确的。但是当数据并不完美时,拟合的准确性就会存在问题。在计量拟合引入时间序列的思想,其意义在于:
- 当残差违反了无自相关的假设,我们实际上也可以把残差视为一个可以利用自相关模型预测的时间序列,从而对预测做出修正(自相关模型,如AR、MA、ARMA)。
- 当残差违反了同方差的假设时,我们实际上也可以把残差的方差看作一个可以预测的时间序列,利用其自相关性对方差进行预测,对残差做出修正(条件异方差模型,如ARCH、GARCH)。
金融计量学的研究目标是金融数据,例如:某一只股票多年的价格序列,我们称之为 时间序列数据;例如某十只股票多年的价格 和各个影响因素,我们称之为面板数据。这两类数据是金融计量学研究的重点,尤其是利用这两类数据进行未来值 预测 是研究的主要目的。
一般来说,能够用于计量分析的金融数据一般:
- 具有一定的 平稳性(均值、方差不随时间变动,因而可以预测)
- 序列的残差具有 自相关性,需要对序列的残差进行自相关性类型的识别,进而选择合适的模型:可能是自回归自相关(AR),也可能是移动平均自相关(MA),也可能是两者都有的ARMA。
平稳性
严格意义的平稳性是强平稳,意味着联合概率密度函数在每个时间点 和时间滞后点 都相同;
广泛意义上的平稳性是弱平稳,代表:
- 在所有时间上都是常数,不依赖于
- 只依赖于 ,不依赖于 ,也就是存在均值回归的性质(可以有一定程度的波动,但是随后总会有很大概率向均值回归,也即是:突然一下走高会慢慢往下降,突然一下掉低了会慢慢往回升)。
误差、残差、回归差、离差
误差Error 又称 随机扰动项 ,衡量模型本身可能包含的错误(总体角度),是随机变量,因此又被叫做噪音。
以下三者存在关系:
- 也就是TSS分解
- 拟合优度,从误差角度看可解释部分RSS占总体TSS的程度,越大说明模型拟合效果越好。 等于1时可以看出就是一条水平直线,所以完全平稳、拟合得非常好的。
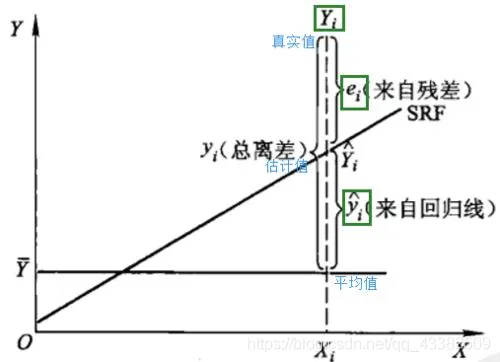
残差Residual ,“残”意味着:是真实值对拟合值的偏离。可以理解为是样本里包含的错误、噪音,也可以认为残差是对误差的估计值。 。我们通过计算,得到的有确定取值的残差,记作 。因此,在模型没有求解出或者说正在求解过程中,残差暂时是未知的,我们写作 ;求出了残差的具体值时,再进行探究就写作。例如:OLS基本假定中,我们用解释变量解出了参数值,得到,因此可以用真实值减去拟合值,得到具体的残差,所以探讨参数是否无偏、一致、最小方差时,我们写作。
回归差,是拟合值对平均值的偏离
离差Deviation,是个体值对总体均值的偏离 ,可以认为是残差和回归差的总和
我们先来速通一遍时间序列分析的思路。
如上面举的例子,某个变量的历史值组成的序列就是一个时间序列数据。对于一个时间序列数据,序列形式就是 某支股票多年的股价 、 一直到 甚至未来的 。根据股价我们也可以求出收益率。总之,我们可以利用时间序列数据的自相关性建立模型,以自回归自相关为例:
这个时间序列数据如果要能够实现很好的预测效果,需要满足:
- 序列具有平稳性(序列自身平稳或经过差分之后平稳才有可能进行预测)并且序列具有非随机性:也就是 序列是非白噪声的平稳序列(对收益率序列的白噪声检验,序列如果随机且平稳,就可能是白噪声从而无法进行预测)
- 残差是白噪声,所以残差是零均值、同方差、无自相关,没有条件异方差性(也就是ARCH、GARCH效应)这样就代表拟合值和观测值的偏离最小,即使有偏离从总体来看也比较稳定。
白噪声的条件
白噪声泛指独立同分布的序列,也就是均值为常数、波动率(方差)有限、无自相关的平稳随机序列。或者说具有同均值、同方差(有限)、无自相关。最广泛的形式:
如果其分布服从正态分布,那么就是正态白噪声。如果均值为零、方差为一,就可以称为标准正态白噪声。
假如在普通的白噪声基础上,还服从正态分布(高斯分布),我们就称其为高斯白噪声(也就是 正态白噪声)。
在下面的内容提到的白噪声,一般默认是均值为0的正态白噪声。
对于第一点 序列是平稳的自相关序列 :
- 首先要确定 序列有自相关性。有自相关的数据肯定不是纯随机的,因此有预测的价值。对存在自相关性的数据,判断其自相关的类型,选择合适的模型进行建模,从而进行后续分析。
- 其次要确定 序列具有平稳性。平稳的序列当前的状态能够延续到未来,因此才可以被预测。上一步自相关模型识别,如果得到的结果是 AR§ ,那么是否平稳需要通过单位根检验来进一步判断;如果得到的是 MA(q) ,那么由模型的自身性质序列一定平稳;如果得到的是 ARMA(p, q) ,需要对其中的AR部分进行判断。
其次,对于第二点, 残差是无自相关的平稳序列,需要进行白噪声检验。由于白噪声是完全无自相关的,因此实际上也是对序列的自相关性进行判断,只不过不同于上一步“序列具有一定的自相关性”,在这里我们希望得到的是“完全无自相关的”、平稳的序列,因此实际应用的方法略有不同。
综合上面两点,就可以对单个序列做出很好的预测模型。而面对多个序列时,如果这些序列本身不平稳,实际上可以把这些序列线性组合、差分处理,对这个经过不平稳序列线性组合、差分出的新序列,用上面的思路进行自相关性识别、建立模型、参数估计、假设检验。因此,此前的单个序列平稳被称之为单整,这里线性组合的新序列的平稳被称为协整,实际上两者思路一致,唯一的拓展就是不仅要关注模型解释变量和被解释变量的相关性,还要关注各个序列间的趋势相关性。
本科《计量经济学》中学的实际上大部分是截面数据,且是静态模型。而时间序列数据建模考虑到自相关性,以序列的历史值(滞后项)作为解释变量,其意义在于拓宽了解释变量的来源,考虑到了滞后效应,把模型变成动态模型。例如研究房价上涨对生育率的影响,由于房价上涨的作用是持续性、滞后性的,因此建模回归时应当将房价变量的滞后项列入解释变量中。这样一来先前诸多关于静态模型的假设,实际上可以放宽,利用自相关性建立相应的模型反映其动态变化即可。
- 残差有自相关:把残差视为一个需要被预测、可以被预测的被解释变量,利用自相关性建立模型进行预测。
- 残差不同方差:对于条件异方差的情况,把方差视为一个需要被、可以被预测的被解释变量,利用解释变量的自相关性建立模型进行预测。
对于此前的静态模型,同样提供了很好的工具来解决此前违反诸多古典假设导致的难以预测的困难,例如可以将被解释变量的滞后项纳入解释变量一方,或者把解释变量的滞后值也纳入解释变量中,从而提高预测的准确性,解决违反古典假定时的动态变化的问题
计量经济学的模型
计量经济学中最基本的模型形式是 ,这实际上是一个静态模型,是针对一个确定的时点的截面数据。
动态模型简单理解就是包含变量的滞后项,也就是认为模型中存在滞后效应。动态模型类型有:
- 自回归模型:无滞后的解释变量 。被解释变量 有长期记忆性。
- 分布滞后模型:无滞后的被解释变量 。解释变量 对被解释变量 有长期影响。
- 滞后变量模型:包含解释变量和被解释变量的滞后项。两者性质都有。
简单介绍其中的重点知识:
自回归模型:被解释变量有长期记忆性。AR(1) 模型实质上可以从三种形式的分布滞后模型变换而来,分别是:Koyck模型、自适应预期模型、局部调整模型。转换的过程在数学上和经济上都具有一定的意义。
分布滞后模型:解释变量对被解释变量有长期影响。可以反映乘数效应。有限的分布滞后可以用经验加权法转化为一元线性回归,或者用阿尔蒙法转化为线性回归函数。分布滞后模型存在很强的多重共线性,解决办法是利用分布滞后的性质:
- 无限几何分布滞后(等比数列)
- NLS: 非线性最小二乘法,令 ,构造 ,P的取值要让 足够小从而不会显著影响 , 的取值要让回归方程有最大的 ,得到的结果代回方程,就是对应的参数估计值。
- Koyck变换为AR(1)。引入延迟算子,把滞后项统一,同理求出 ,求出 就消去了各个解释变量的滞后项,变成 AR(1)。如果新的残差项符合古典假定,就可以用OLS估计参数的估计值。
- 可用多项式描述的分布滞后(多项式曲线描述)
- 阿尔蒙法,假设每个系数都是阶数的多项式,利用这个多项式的系数去代替原本的系数做出新的回归方程。
- 滞后变量模型:可以推导出误差修正模型:对滞后变量模型两边同时减去 ,经过化简,原模型的变量就都是差分化的变量,因此具有平稳性,可以避免伪回归。即使变量本身不平整,只要其线性组合出的新序列平整也就是具有协整性,那么此时ECM的随机误差项就具有平稳性,所有差分变量也具有平稳性。
总而言之,解决动态问题的核心就在于把存在动态变化的、需要被预测的变量视为被解释变量,利用其自相关性建立相应的模型进行动态的预测(很像套娃,不断重复“不平稳的就用动态模型做预测,直到得出平稳的”结论)。归根结底,都是希望得到两个特点:
- 序列有自相关的平稳序列(模型识别、单位根检验),所以可以用自相关模型预测序列。
- 残差是无自相关的平稳序列(白噪声检验),所以可以用白噪声描述残差。
总的方法都是围绕自相关的有无展开,主要就是:
- 平稳性检验(识别自相关类型,AR的话就进一步做单位根检验)
- 白噪声检验(判断完全无自相关性)
本文为了方便解释这两大方面的知识,按实际操作顺序进行讲解:
- (序列)平稳性检验
- (残差)白噪声检验
- (条件异方差)模型优化
(序列)平稳性检验
平稳性的含义
稳稳的幸福,就是爱你始终如一
平稳性
严格意义的平稳性是强平稳,意味着联合概率密度函数在每个时间点 和时间滞后点 都相同;
广泛意义上的平稳性是弱平稳,代表:
- 在所有时间上都是常数,不依赖于
- 不依赖于 ,只依赖于 的变量。存在均值回归的性质(可以有一定程度的波动,但是随后总会有很大概率向均值回归,也即是:突然一下走高会慢慢往下降,突然一下掉低了会慢慢往回升)。
现在我们深入研究时间序列数据。
首先针对单变量的时间序列进行分析。直观理解平稳性,下面四幅图,可以看出来:
- 第一幅是白噪声,完全随机,是 平稳序列;
- 第二幅随机游走,没有固定趋势,均值、方差波动程度较大,是 非平稳序列;
- 第三幅趋势上升,但均值随时间增加而增加,是 非平稳序列;
- 第四幅曲线大致在一条水平线上下波动,波动程度前后变化较小,均值没有明显随时间变动,可以认为是平稳的。第四幅是第三幅差分后的结果,可以看到像第三幅这样的不平稳序列,实际上也是有可能通过求差分变平稳的。

纯随机的序列叫随机游走序列。
随机游走
DF原假设是:,实际上这就是随机游走的含义:一旦,说明序列值取决于白噪声,因此任意的序列值 都可以表示成历史白噪声的组合 所以任意序列值不会超过历史白噪声的总和,序列值就会是完全随机的,如同醉汉摇摇晃晃乱走路(Random Walking),即随机游走。随机游走的数据的特点:
- 零均值
- 方差和t相关 ,所以数据不平稳
随机游走序列可表示为历史白噪声的线性组合,因此对这个式子两边同时求方差,不难看出,结论是 ,意味着方差是随时间变化的函数,不符合协方差平稳的条件。
自相关的含义
为了更好地预测时间序列数据,我们就要深入探究序列自相关的形式,确定具体的 自回归的模型类型(AR、MA、ARMA) 和模型阶数 (p、q)。序列自相关可能是像上面说的:
- 受历史值影响;
- 受噪音影响。
第一种模型我们称之为自回归AR(Auto regress),即现在的自己受到过去的自己的影响,也就是自回归;第二种模型我们称之为移动平均MA(Moving average),即现在的值受到冲击因素(噪声)的持续影响,影响随时间逐渐减弱。当然也有第三种模型也就是综合起来考虑的ARMA(Auto regress and Moving average)模型。序列自相关性影响的范围就是自回归模型相应的阶数。如果进行深入研究,时间序列的相关研究引入了序列相关性的概念,实质上是计量经济学中研究动态模型的重要基础。
为了描述自相关性,计量经济学常用自相关系数ACF和偏自相关系数PACF。我们这个模型为例讲解ACF和PACF的含义
自相关函数ACF
例如我们有一个 序列,ACF的原理可以认为是利用滞后k期的滞后周期,取出两个等长的子序列(例如第一个是到,第二个是到,这就是滞后k期的含义),分析他们的相关性,因此ACF反映了存在时滞周期k的两个子序列之间的相关性,实质上体现的是自己和滞后k期的历史值之间的相关性。
偏自相关函数PACF
实际上可以这么理解:我们对时间序列模型建立AR§自回归模型,此时被解释变量是t时刻序列值 ,解释变量是其滞后项 。滞后项的系数 可以反映解释变量 的变化对被解释变量 变化的影响作用,因而 PACF实质上剔除了中间其他时期的序列值的影响,直接反映了不同时期序列值之间的相关性。
阶数的判断,一般而言是指在某一阶之后序列为零,或序列处于置信区间内。实际模型的选择一般需要看AIC、BIC信息准则,选择有最小信息准则的模型。
一般而言,平稳序列的自相关函数、偏自相关函数会迅速退化到0,滞后期越短,相关性越高(滞后期为0相关性为1)。因此假如自相关函数退化比较慢、或者存在周期性波动、或者存在先减后增等情况,也就是意味着较多的相关系数在边界外,自相关函数没有截尾或者拖尾,说明序列不平稳。因此我们需要重点关注ACF、PACF的特点。迅速退化的这种特点,被我们分为截尾和拖尾两种情况:
- 截尾 :在某一阶之后等于0;
- 拖尾 :某一阶之后都在区间内徘徊(自相关系数呈现余弦衰减)。
假如自相关函数退化比较慢、或者存在周期性波动、或者存在先减后增等情况,也就是意味着较多的相关系数在边界外,自相关函数没有截尾或者拖尾,说明序列不平稳。因此,我们可以通过ACF、PACF对模型的自相关性进行识别,进而判断序列是否平稳。
| 数据自相关类型 | ACF | PACF | 考查重点 | 平稳性 |
|---|---|---|---|---|
| 拖尾 | 截尾 | 动态路径 | 需要进行单位根检验 | |
| 截尾 | 拖尾 | 冲击因素 | 一定平稳 | |
| 拖尾 | 拖尾 | 二者皆有 | 判断其中的AR部分 |
此外,还有一种方法,叫MTV(min table value)法也即是最小表格值法。它会给你一个表格,表格横轴和纵轴分别是不同阶数的AR、MA。表格内部的值表示的是MTV的取值,最接近2的那个模型就是最合适的模型,这就是我们关于模型的识别。
数学角度的推导和结论
概率论中,协方差 用来衡量两个变量之间的相关程度
协方差 用来衡量两个变量之间的相关程度
Cov(X, Y)&=&E\left[ (X-E(X))(Y-E(Y)) \right] \\ &=&E(XY)-E(X)E(Y)
- 协方差大于0,那么X和Y正相关(说明X和Y总体上看是同向变动);
- 协方差小于0,X和Y负相关相关(说明X和Y总体上看是同反变动);
- 协方差等于0,两者不相关(没有相关趋势)
如果在时间序列中求协方差 ,由于对象是自身 和自身滞后值 ,因此这样的协方差称之为 自协方差,有性质:
由于X和Y的量纲可能存在差异,例如中国的猪肉价格X和美国的猪肉价格Y,一个是用人民币来计价,一个用美元来计价,因此两者变动的幅度不一定相同,这会导致两者的相关性被放大或者被缩小,相关性分析就不准确了。
因此,对协方差进行归一化得到 相关系数,就可以消除了量纲差异,类似于线性代数里向量的标准化,使不同维度的数据可比,可以准确判断相关性。
相关系数 是对协方差进行归一化得到的,消除了量纲差异,类似于线性代数里向量的标准化,使不同维度的数据有具体的范围、相同的幅度可比,可以准确判断相关性的强弱,-1是完全负相关,+1是完全正相关,取值范围是:。
计量经济学中,对这些工具做了拓展:
自协方差
如果在时间序列中求协方差 ,由于对象是自身 和自身滞后值 ,因此这样的协方差称之为 自协方差
并且有重要性质:
- 有偏估计
- 无偏估计
- ,
偏自相关系数
实际上就是和两个时点间的相关系数,“偏”是借用偏导数的定义,体现“点到点”之间相关性的特点。
在下面的AR§模型中, 实际上就是滞后k阶项的系数 。
自相关系数
可以看出,实质上反映了滞后h期与当前的相关性。
ACF和PACF反映了相关性的程度、特点,其计算是通过下面的自相关模型参数估计推导出的。
AR模型
具体来说,假如我们认为 当期值是过去值的线性组合加当期白噪声的结果,意味着 和 自相关也就是 具有自相关性,我们就会构建AR模型,也就是意味着我们可以 用 自己的历史值预测自己未来值,这个历史的范围就是滞后的阶数p。
我们可以把含截距项的 AR§ 模型转化成 不含截距项的形式。假如 AR§ 的均值是 ,那么可以对原模型去均值化,得出
这样,就可以将含有截距项的模型构造成一个不含截距项的新模型
由于做了去均值的处理,这个新模型的均值就等于0,是均值为0的AR§模型,下文的 Yule-Walker方程就是基于这样的模型建立的。
AR§ 的高阶自回归模型
可以写成向量形式
AR模型的核心知识:
- 平稳性的判断(单位根检验)
- 和自相关系数的联系 (Yule-Walker方程)
- 参数估计的方法
- Yule-Walker方程 估计
- 最小二乘估计
- 极大似然估计
单位根检验
单位根检验,对于AR(1)叫DF检验,AR§叫ADF检验。下文以高阶AR为例讲解单位根检验。
AR§ 平稳的含义是:AR§ 所有滞后项系数 ,等价于特征方程不存在单位根,解都大于1在单位圆外。由于需要求解的个数较多,我们可以引入滞后算子 ,把滞后项全部转换成 ,就可以得出:
平稳性的判断,等价于分母这个关于滞后项系数 的 特征方程 的求解情况,当且仅当存在单位根,分母为0。因此,化简构造特征方程=0,并判断:
如果 特征方程无单位根,那么序列平稳,这个条件等价于上面的 如果所有滞后项系数 那么序列平稳。数学上把模长等于1的解称之为单位根,考虑实数域和虚数域,从几何上看,单位根是落在单位圆上的,即 $\lVert L \lVert =|L|=1 $。一旦有这样的单位根,就意味着方程是随机游走模型,序列值是纯随机的,不符合平稳性的定义。无单位根 可以简单理解为:特征方程所有解都大于1,不存在模长等于1的解。之所以用求解特征方程的方法来判断平稳性,是因为只需要解方程,判断是否有解模长(因为可能是复数)等于1即可。而直接判断滞后项系数,需要判断绝对值是否小于1,比解单位根麻烦。
之所以叫单位根,是因为解出的结果很可能是复数,因此引入复平面上单位圆的概念,判断方程的解是否会落在单位圆上,也就是判断得到的复数解的模是否等于1。引用知乎上的回答中的内容:


因此,同样列出假设,并求出解的情况进而判断平稳性,这就是单位根检验的做法和原理。
- 原假设:存在 ,等价于存在 ,也就是特征方程存在单位根,意味着序列不平稳。
- 备择假设:任意 ,等价于 ,也就是特征方程不存在单位根,意味着序列平稳。
对于不平稳的序列,可以尝试进行差分,再进行单位根检验,例如:数据如果进行3阶差分后平稳,就称之为3阶单整,记作I(3)。
假设检验的原理
假设检验的原假设是:某个小概率事件会发生。置信度水平α是这个小概率事件发生的可能性的最低要求。生活中我们一般认为:当事件发生的可能性小到一定的程度,那么就可以认为这个小概率事件不会发生,也就是说应该拒绝
这个事件会发生的原假设,反之如果事件发生的概率大于一定的程度,就不能认为这个事件不会发生,不能拒绝原假设。另一个角度,α是原假设为真时拒绝原假设的概率的临界值,被称为去真概率的临界值也就是置信度水平,如果得到的实际的去真概率P值小于临界值,说明不会去真,应该拒绝去真的原假设;反之,去真概率P大于临界值,说明去真这个原假设不是不可能发生,不能拒绝原假设。
另一个角度,1-α是:当原假设为真的时候,接受原假设的概率,也就是不去真的最小要求,如果计算得出的1-P大于1-α这个最低要求,说明不可以拒绝原假设;反之应当拒绝原假设。
需要注意的是,这里判断的结果是:
不拒绝原假设
拒绝原假设(不是接受备择假设)
由于我们假设检验构建的统计量、P值都是针对原假设的,因此得出的结果也是关于原假设的结果。备择假设的含义是:选取一个和原假设对立的假设条件,因此当我们通过统计检验得出拒绝原假设的结论后,可以考虑选取备择假设作为备用选择。因为假设检验是针对原假设做的检验,而没有检验备择假设,所以假设检验的得出的结论应该表述为拒绝原假设,而不能直接说接受备择假设。
检验的类型有单侧检验、双侧检验。上面是以单侧检验为例讲解的,置信度是去真概率的临界值,对应的t统计量就称之为 上 分位点。 如果是双侧检验,实际上可以通过取绝对值,转化为单侧检验。双侧检验的去真概率实际上来源于两侧,以t分布为例,左右各占 ,取绝对值后,只看正区间,可以认为此时去真概率的临界值是 ,接下来就可以单侧检验的方法进行判断。
形象化理解:
以谈恋爱和别人约会为例, 是你的约会对象, 是潜在可约会对象,置信度 是你认为的约会的好感。假设检验的过程,就是约会判断对 好感的过程,假如完全没达到你心中的预期,那么你一定会拒绝和他继续发展;假如这种好感足够大,你就不会拒绝和他继续往下发展。假如你拒绝和他继续往下发展,就可以考虑此时潜在的其他约会对象例如 。
单侧检验的概率就是:你知道他是你的真命天子,但你拒绝了他的概率。假如这个概率足够小,就可以认为你不会拒绝你的真命天子。
双侧检验的概率就是:首先是统计量的含义,越往右是约会对象表现得越好,越往左是约会对象表现的好坏程度。实际上你心中对约会对象有一个预期的上限和下限,如果他表现得超过你的预期的上限,你会认为他是伪装出来的假象,他太虚伪了,所以会拒绝他;如果他表现得太差没有达到你预期的下限,你也会觉得他不够好,也会拒绝他。
另一种理解:
以刑事审判作比喻,我们假设被告是无辜的,接下来我们询问证据是否与假设相符?如果不是,我们可以拒绝假设,即被告不是无辜的;如果是,我们无法拒绝,即不能证明被告不是无辜。注意:不要“接受”假设
参数估计
Yule-Walker方程
对于均值为0的 AR§ 模型,如果和自相关函数联系起来,就可以得到Yule-Walker方程。作用是:
- 根据AR§模型,进而推出自相关系数和偏自相关系数
- 参数估计
主要的结论和性质如下:
对任意自协方差,当 ,有
PACF 得到的就是序列滞后项的系数,因此这也是AR模型的参数估计方法之一。当然,这一估计存在一些问题,因此我们更常用最小二乘估计或极大似然估计。
Yule-Walker方程的相关推导及性质
两边同时乘以,然后式子两端同时取均值,利用公式 ,并且由于是白噪声所以有 ,上式就变为
即 ,同理,分别对原式乘 、 等滞后项,并求均值,可以递推出剩余各式
整理为矩阵,就是
并且,对任意自协方差可得出递推式(加绝对值是因为要让步长为正数),有
其中 是自协方差矩阵, 是偏自相关系数PACF向量, 是自协方差向量。
可以根据求相关系数 的方法,对自协方差向量 数乘 ,得到 相关系数ACF向量
根据Yule-Walker模型,可以得到滞后项的系数估计值,也就是PACF
Yule-Walker的估计实质上存在一些问题:
- Yule-Walker建立在均值为0的AR§模型基础上,假如不为0就会利用去均值化的方法构造均值为0的新AR§序列,这个过程会引入误差。
- 对自协方差进行估计时,由于使用的样本不一样,估计的准确程度就会不一样
- 作为方差的估计量,不能完全保证方差一定为正数,会产生逻辑上的矛盾。
极大似然估计
似然函数是
求出 就可以求出参数估计值。
极大似然估计
假如知道某个事件服从某种概率分布模型,例如 服从正态分布,但是不知道正态分布这个分布模型的具体的参数取值,就可以采用极大似然估计,来获得从已知的概率的角度(例如:已经确定事件X服从正态分布,仅仅不知道正态分布的具体形状)的最有可能的参数取值。示例:已知男生和女生身高的分布都各自符合正态分布,现在有一堆样本点,需要判断这一堆样本点的数据的性别。
根据假设的条件概率(参数未知的概率分布模型),列出似然方程并求解最大值,得到的估计量就是极大似然估计,也就是直观认为最有可能发生的概论的估计。图中样本点从概率角度来看,最符合蓝色的正态分布,因为绝大多数样本点都分布在蓝色的模型中,并且分布的密度和蓝色正态分布模型的密度十分对应。概括起来:
似然 就是:根据这一堆样本点,寻找合适的概率分布模型
概率 就是:根据已知的概率分布模型,寻找某个取值出现的可能性极大似然估计的特点:
- 比其他估计更简单
- 收敛性:无偏性,或渐进无偏,样本数量增加收敛性质会更好。
- 条件概率的假设至关重要,假设如果出现偏误,估计结果会很差。也就是:不一定有最小方差性

最小二乘估计
VAR模型
假设多个序列线性组合的新序列也具有平稳性,那么称之为协整。利用单个序列的思想,线性组合出的新序列应该也是存在自相关的,那么同样判断:
- 新序列是有自相关的平稳序列
如果自相关类型是MA,那么必然平稳,此处由于是向量形式,记作VMA。因此,需要进行判断的是向量形式的AR模型的平稳性,记作VAR。进一步地,可以建立误差修正模型,解决多维数据存在的多重共线性问题。
此处以VAR为例,讲解多维数据的处理思路与方法。
协整检验(平稳性)
针对单个序列,可能存在的平稳性我们称之为单整。而如果我们有多个序列,即使这些序列自身不平稳,考虑序列之间长期存在的关系,统一经过 阶差分、线性组合出新序列是平稳的,我们就称:这些序列间存在协整关系。协整关系如果存在,说明多个序列可能各自都有波动(序列自己不平稳),但长期来看有相同的变动关系或者叫变动比例(同甘苦共患难,同起落),那么他们线性组合出的新序列平稳。
例如:设居民收入时间序列 为1阶单整序列,居民消费时间序列 也为1阶单整序列,如果二者的线性组合构成的新序列 为0阶单整序列,则可认为序列 与之 间是(1,1)阶协整。
经济意义:两个变量,虽然它们具有各自的长期波动规律,但是如果它们是协整的,则它们之间存在着一个长期稳定的比例关系。例如居民收入 和居民消费 ,如果它们各自都是1阶单整,并且它们是(1,1)阶协整,则说明它们之间存在着一个长期稳定的比例关系,而这个比例关系的度量就是“消费倾向”。长期来看,消费倾向应该是不变的。
协整关系可能存在于:
- 一元线性回归,Y和X之间,这样的协整称之为一阶协整;
- 多元回归或有X的滞后项,多个时间序列数据(VAR模型)、面板数据等,这样的协整称之为多阶协整。
不同协整类型判断方法不同:
- 一阶协整:Engel-Granger两步法(EG)
- 多阶协整:Johansen检验(JJ)
重点讲EG的过程,从原理上看,EG检验其实就是:
- 对Y和X进行OLS,目的是得到残差
- 对残差进行ADF分析,如果平稳,则存在一阶协整,不平稳则不存在一阶协整
其假设是:
- 原假设:无协整
- 备择假设:有协整
格兰杰检验(序列间相关性)
对多个序列进行分析后发现,序列的线性组合平稳,因此序列之间或者是序列的线性组合具有平稳性。以多阶协整为例,多阶协整存在于Y和多个X之间,说明序列间可能存在变动趋势的相关性。所以我们还可以对变量间的关系进行研究,观察是否有某个变量的历史值对另一个变量的现值有影响(有影响,代表可以用这个原因去预测需要的结果),这种关系我们称之为格兰杰因果,具体来说有四类:
\ce{X_{t-i}&->[引起]&Y_t} \qquad&\text{$\sum_{i=1}^{m}a_i$ 显著不为零,$\sum_{i=1}^{m}\beta_i$ 显著为零,X是Y的格兰杰原因} \\ \ce{X_t&->[引起]&Y_{t-i}} \qquad&\text{$\sum_{i=1}^{m}a_i$ 显著为零,$\sum_{i=1}^{m}\beta_i$ 显著不为零,Y是X的格兰杰原因} \\ \ce{X_{t}&<->[相互影响]&X_t} \qquad&\text{$\sum_{i=1}^{m}a_i$ 显著不为零,$\sum_{i=1}^{m}\beta_i$ 显著不为零,X和Y互为格兰杰原因} \\ \ce{X_{t}&<->[互不影响]&X_t} \qquad&\text{$\sum_{i=1}^{m}a_i$ 显著为零,$\sum_{i=1}^{m}\beta_i$ 显著为零,X和Y不互为格兰杰原因}\\如果发现某个变量A是另一个变量B的格兰杰原因,说明这个变量A的滞后值能提高预测另一个变量B的能力,A的前期变化可以引起Y现在的变化。特别注意,格兰杰检验可以反映的是统计意义上的因果关系。
数学形式是:
- 原假设H0:A不是B的格兰杰原因,A不能引起B的变化
- 备择假设H1:A是B的格兰杰原因,A可以引起B的变化
例如下面

- 投资额对销售额的检验不显著(数小率大),不拒绝H0;
- 销售额对投资额的检验显著(数大率小),拒绝H0,选H1,销售额是投资额的格兰杰原因。
误差修正模型
MA模型
假如我们认为当期值是历史白噪声的线性组合,大部分时候的时间序列数据就像池塘里的水是稳定的,除了偶尔因为风吹草动、丢石头这样的冲击因素导致波动,这就意味着不同时间的Yi没有自相关性,不能拿Yi的过去值来预测,而是应该用白噪声的线性组合来预测。
历史白噪声的范围,就是滞后的阶数q
AR和MA的转化
\ce{AR(1) & <->[Koyck转换] & MA(\infin)} \\ \ce{AR(\infin) & <->[可逆性] & MA(1)}ARMA模型
我们也可以综合考虑,认为两种情况同时存在。这就是我们的ARMA模型。其实也很好理解:
以MA模型为基础,把 这一期的白噪声 替换为AR模型,可以认为这一期的白噪声的作用等同于 历史值线性组合的作用,这就是ARMA公式的由来
可以对ARMA模型进行I阶差分处理,以图消除趋势、季节性因素,得到ARIMA模型
- AR部分考虑过去值对现值的影响,参数是p
- MA部分考虑过去预测的误差对当前值的影响,参数是q
- I部分代表平稳化,参数是d
总结
平稳性针对单个序列,称为单整;针对多个序列并研究多个序列的线性组合的平稳性,称为协整。
单整的类型是:所有的MA(q)和特定的AR(q)。对AR(q)的平稳性的检验方法是:DF和ADF检验,原假设 都是AR模型存在单位根,序列非平稳,备择假设 是平稳。DF针对的是AR(1)一阶自相关的情况,ADF是对 AR(1) 高阶的拓展。核心思想都是:研究是否存在滞后项系数绝对值不小于1,等价于判断特征方程是否存在单位根。
协整又分为一阶协整(Y和X)和多阶协整(存在多个X的滞后项):
- 一阶协整的检验方法:Engel-Granger两步法,对于多个序列,如果序列不平稳则可以尝试差分,目的是得到 阶单整序列,进而OLS得到残差,最后对残差进行ADF检验,残差平稳则有协整。
- 多阶协整的检验方法:Johansen检验
存在协整的数据可以进一步做格兰杰检验,考虑序列间是否存在统计意义上的因果性。
(残差)白噪声检验
人生总是起起落落、起起落落…
我们现在已经确定了序列是有自相关的平稳序列,为了让残差是无自相关的平稳序列,接下来就要 对残差进行白噪声检验,这是因为 :
- 确定残差是白噪声,意味着残差项序列没有自相关,是随机的,符合古典假定,OLS估计是准确的;
- 如果序列残差存在自相关性,残差就不是随机的白噪声,违反古典假定,OLS估计不是准确的。
Barlett定理
时间序列数据如果纯随机,对于其n期的观察序列,其滞后k期的自相关系数 的估计值 在的时候,近似服从均值为零、方差为观察期n的倒数的正态分布
为了让时间序列预测准确,序列的残差就必须要符合古典假设,即均值为零的正态白噪声。因此,根据Barlett定理,判断序列是否存在一定的自相关性,就能知道残差是否会违反古典假设。所以这里进行的实际上是“针对残差的白噪声检验”。
白噪声检验,需要判断完全不存在自相关。判断的方法:
- PACF、ACF如果显著不为零,必然存在自相关性。
- 构建Q统计量,研究ACF的分布,例如BP检验、LB检验,判断序列的残差在整个序列上的自相关性ACF是否满足临界值的卡方分布:
- ==:假如残差序列上完全不存在自相关性这个假设的满足临界值的卡方分布,可能性足够强,零均值、同方差的序列残差就是随机的,也就是说残差无自相关,满足白噪声的所有假定,所以残差是白噪声==
- ==:假如原假设残差序列上完全不存在自相关性这个假设的满足临界值的卡方分布,可能性不够强,那么就要拒绝原假设,可以认为存在一定的自相关性,残差项肯定不随机,不符合白噪声无自相关的假定,因此残差不是白噪声。==
Box-Pierce检验法
我们可以利用假设检验,构建关于ACF的Q统计量,认为应该服从某些分布。根据 Barlett定理,当序列如果有足够的自相关性时,这个序列必然不是白噪声。因此,Box-Pierce检验法用序列的自相关系数ACF构建 统计量,并和卡方临界值 对比,检验序列的整个m阶时期内是否存在足够的自相关性。
m是最大滞后阶数(一般是手动设定,是临界值的自由度),n是观察期数, 是k阶自相关系数ACF的估计值。
此处我们检验残差自相关性的程度,检验对象是序列的残差的所有m阶自相关系数 。假设ACF的分布满足临界值的卡方分布 :
- ==:m阶自相关系数均为0,残差完全无自相关,那么零均值同方差,是白噪声==
- ==:假如原假设残差序列上完全不存在自相关性这个假设的可能性不够强,因此要拒绝原假设,可以认为存在一定的自相关性,那么残差项肯定不随机,不符合白噪声无自相关的假定,因此不是白噪声。==
同样是用那个口诀,数小率大接受原假设。
Ljung-Box检验法
第三个方法是Ljung-Box检验法,可以理解为是BP检验的改进升级版,反正最后使用起来也是对比构建的QLB统计量,数小率大接受原假设。LB检验同样假设ACF、PACF符合某种分布,序列的残差在整个序列上自相关性的程度:
- ==:假如残差序列上完全不存在自相关性这个假设的可能性足够强,零均值、同方差的序列残差是随机的,也就是说残差无自相关,满足白噪声的所有假定,所以是白噪声==
- ==:假如原假设残差序列上完全不存在自相关性这个假设的可能性不够强,因此要拒绝原假设,可以认为存在一定的自相关性,那么残差项肯定不随机,不符合白噪声无自相关的假定,因此不是白噪声。==
(条件异方差)模型优化
一个套娃解决不了问题,那就再套一个…
之前的模型之所以完美,有两方面的原因
- 序列是平稳的自相关模型
- 残差是平稳的无自相关模型
当残差不再是完美的白噪声时,条件异方差模型给出了一种解决思路。
OLS古典假定中,残差 是白噪声,所以是同方差的。但现实中的其他时间序列经常存在波动集群的现象,大波动后跟着大波动,小波动后跟着小波动,例如:2008年金融危机爆发的时候股价波动极为猛烈,而在其他时候股价变动会比较平缓。
为了描述这种波动集群现象,我们用残差 来代替随机误差项 ,引入残差的条件异方差模型。核心是:把残差的波动率视为方差 ,条件异方差意味着:残差的方差 也就是波动率不是常数,而是一个随时间t变化而变化的函数 ,违反计量经济学古典假设 同方差 的假定,这会导致OLS出现误差。
波动集群
形象地理解,序列值 受残差 的影响,残差 受其自身方差 的影响,而残差的方差 是受残差的平方滞后项 影响…因此一旦在 时刻有一个突发事件,表现为 的波动变大即 扩大,那么 时刻的方差就会受过去的残差平方 的扩大而变得更大,进而 的波动就会进一步变得更大,以此类推,也就是
- 大波动跟着大波动;
- 反之 小波动跟着小波动
因此对于这个不确定的方差(残差的波动率),ARCH模型和GARCH模型用类似于此前我们利用时间序列 的序列相关性来预测一样,利用方差的序列相关性来预测方差 。要弄清残差的条件异方差性(conditional heteroscedasticity),就要重点研究 的残差自身的特点。你可以认为残差的条件异方差性的由来就是:残差项 在q个滞后期上分布特点不同,存在条件异方差性 。所以ARCH模型、GARCH模型利用这一点,把方差 作为被解释变量,进行建模、预测。
- ARCH模型基本思想是:残差 在时刻的方差 和历史q期的残差平方 存在序列相关性(并且是同向的),并且 自身是服从AR(q)自回归自相关的,因此残差 存在波动集群的性质就可以用历史q个时刻上的残差平方 存在作为解释变量去回归方差 。
- GARCH模型则在ARCH基础上,认为 自身也存在p阶自回归自相关,因此解释变量既包括历史时刻上的残差平方 ,还包括 被解释变量的滞后项 。
序列相关性,个人理解侧重于体现两个 不同时点 的数据之间的相关性,突出的是时间序列的特征。
可以看出条件异方差的经济含义是很明确的:将资产的波动率描述为条件异方差,条件异方差代表资产波动率不为常数,而是一个随时间变化的函数,就可以用方差的情况来体现资产的风险。。
ARCH模型
含义
古典假定中随机扰动项 是同方差的,所以残差作为随机扰动项的估计,应该是同方差的,不应该有条件异方差性,残差的波动率 应该是一个常数,而不应该是一个关于 的变量。
在ARCH模型中,残差存在波动集群的性质表示为:残差 在时刻的方差 和历史q期的残差平方 存在序列相关性(并且是同向的),并且 自身是服从AR(q)自回归自相关的,就可以用历史q个时刻上的残差平方 存在作为解释变量去回归方差 。此时作为解释变量的历史残差平方项 就不能是白噪声,否则就会因为具有随机性,无法预测被解释变量波动率 ,没有预测意义。据此,有ARCH效应的模型在数学上定义为:
- 残差自身 存在自回归自相关,有条件异方差性,不是白噪声 ,存在关系 ,是一个白噪声;
- 残差的方差 和残差滞后项的平方 存在q阶序列相关,因此方差不是恒定的常数,不是白噪声;
- 残差的平方 存在q阶自相关,不是白噪声。实质上是 服从 AR(q), 不是整个序列上都没有自相关(有q期自相关)。
其中 是 的随机误差项,是白噪声。同时,为了保证 是非负数,,,
如果不存在ARCH,其实就是:
- 是零均值、同方差、无自相关的白噪声
- 同方差,所以方差是一个常数,均值不为零、方差为零、有自相关性,不是白噪声
- 所以 也是零均值、同方差、无自相关的白噪声
用于预测的量肯定不能是白噪声,这一原理的应用,整理如下:
- 【OLS】序列平稳且不是白噪声,否则无法预测
- 【ARCH模型】 不能是白噪声,否则无法预测
你可以这么思考,假如出现一个冲击事件,就会导致某一期开始白噪声特别大,反映到波动率上波动率自然也会变大。也可以看出来冲击事件的传递是持续性、有回声的,就像往池塘里扔石头,水波开始扩散然后一段时间越来越弱渐渐消逝。
因此 ARCH效应 其实应该准确地定义为: (残差的平方 是)自回归(并且残差 有)条件异方差( )的效应。ARCH效应存在,我们通过建立ARCH模型可以得到:方差不是常量,所以可以利用方差 和历史残差项的平方 有序列相关性,来预测,因此解释变量 不能是随机的,模型假设 服从AR(q)模型,表现为 不是整个序列上都没有自相关(有q期自相关)。
ARCH模型实际上是AR模型在上的拓展应用,同时利用方差 和的序列相关性,对方差 进行预测。意义就在于:通过对残差波动率也就是方差 的准确预测,修正残差的条件异方差性给预测序列值带来的偏误,提高预测序列值的准确性。
检验
在ARCH和GARCH中, 作为解释变量,不能是随机的,表现为 不是在整个序列上都没有自相关(有q期自相关)或不是白噪声。 条件异方差的实际的操作,就是利用自相关性的程度的判断(利用ACF、PACF构建Q统计量,探究Q是否满足卡方分布的临界值)来进行的,从 的ACF、PACF的角度来看:
- ACF(BP法、LB法):判断 的自相关性是否足够弱,如果够弱,就不能认为序列一定不是白噪声,从而不能认为被解释的 一定是一个常数,没有条件异方差;如果不够弱,那么序列不应该完全无自相关,所以是非随机的,可以认为不是白噪声,可以认为不是常数,而是具有条件异方差效应。
- PACF(LM法):根据 和 序列相关,计算 这个方程的拟合优度,等效于对 进行自回归检验,也就是分析 在m阶滞后范围内的自相关是否显著。拟合的足够差,说明这个方程不显著,方程的解释变量自回归的特点也不显著,不存在足够的自相关性,可以是白噪声。
有的同学就会问:之前讲计量的时候,还不是介绍过其他判断异方差的办法吗?为什么条件异方差的判断不用对异方差本身的判断方法呢?其实是因为每种方法适用的对象和假设的前提不一样。异方差的判断方法,例如:
- GQ检验的对象是递增型异方差,原假设同方差,备择假设存在递增型异方差;
- Glejser检测对象是递增或递减型异方差,原假设同方差,备择假设递增或递减型方差。并且可推出异方差形式。
此处 存在条件异方差体现出来的是: 是q阶自回归自相关AR(q),所以不随机不是白噪声,所以方差 是随t变化而变化的函数而不是一个常数。因此,条件异方差的判断主要是集中研究:这q期的 的自相关的程度是否足够强(满足临界的卡方分布)。这种条件异方差不一定是纯递增或纯递减,使用情况不一样。
ARCH-LM法(PACF)
从的角度出发,由于ARCH模型认为它服从AR§,因此可以用拉格朗日乘子检验(LM法),目的是探究残差的平方有没有自相关性(和过去几期)。
ARCH模型的第一个式子是 和 存在序列相关,这个式子作为我们的主回归函数;另一方面,ARCH模型假设,所以我们也可以据此建立关于的AR§模型作为辅助回归函数。根据模型的含义,考虑到 是非负数,,,。
可以发现第一个式子中, 对应的 滞后项的系数实质上就是 的偏自相关函数,这两个式子实际上是一致的。这代表可以从两个角度来理解LM法
- 拉格朗日乘子检验(LM法)检验主函数的拟合优度 来构建Q统计量,并与临界值 比较,看模型拟合得是否足够差,足够差,说明模型自身解释变量是随机的,不具有预测的功能。其中,P是模型中滞后项的系数的个数。
- 检验解释变量的自相关性是否足够弱,如果足够弱,说明是随机的,用这些随机的解释变量得到的方差就必然是一个常数。
不存在自相关 等价于 有随机性,不是白噪声 进而可以推知 无条件异方差性
因此,假设其实就是:
- 原假设是:无ARCH效应。滞后项的系数也就是的偏自相关系数PACF都等于0,那么 整个序列都没有自相关,那么方差就是恒定的常数,无ARCH效应。或者从另一个角度来说就是 历史噪声平方项 是白噪声,不存在自相关。
- 备择假设是:有ARCH效应。方程存在 的系数 ,存在自相关性所以不是纯随机的,那么方差不恒定,有ARCH效应。
还是那个道理,我们不可能拿随机的东西来做预测。如果白噪声的平方也是白噪声,那么它的线性组合肯定也是随机的,预测不出波动率。因此,历史噪声平方项 不能是白噪声。
LM法构建的是F统计量,还是一样用口诀(数小率大选H0)判断就可以
BP法
全称Box-Pierce检验法,一定要注意全称避免看错!!!
根据,分析 自相关系数ACF的情况,检验m阶滞后范围内自相关是否显著。m阶是潜在可能的最大的延迟阶数,也就是ARCH模型里潜在的q的最大值。实质上就是对 进行白噪声检验:完全无自相关的肯定具有随机性,此时 符合白噪声条件,的方差是常数,不存在条件异方差。
整个平稳序列所有自相关系数等于0、完全无自相关性的这种假设的可能性足够大,满足临界值的卡方分布 时,就有足够强的理由不拒绝原假设H0“认为完全无自相关”, 时白噪声,此时 不存在条件异方差。
- ==: 在m阶内均无自相关,此时 满足白噪声的所有假定, 是白噪声;==
- ==: m阶内不是完全无自相关,因此 不是白噪声。==
优点在于:大样本时效果很好 ( 就是大样本,有研究说n在500这个量级统计检验效果较好)
不足在于:小样本时不太精确。
LB法
不存在自相关 等价于 有随机性,不是白噪声 进而可以推知 无条件异方差性
从 不是白噪声这个角度出发,ARCH效应判断等价于进行的白噪声判断,因此可以选用BP法、LB法。
LB检验是BP检验的改进,现在小样本也精确了:
- ==: 在m阶内均无自相关,此时 满足白噪声的所有假定, 是白噪声;==
- ==: m阶内不是完全无自相关,因此 不是白噪声。==
GARCH
在arch模型的基础上,假如我们认为波动率不止受白噪声的平方滞后项影响,还受到波动率的滞后项影响,那么就可以建立garch(广义自回归异方差)模型,其实就是arch的扩展形式Generalized ARCH,或者说arch是广义arch的一种特殊情况,最大的特点都是存在条件异方差性。所以可以用检测ARCH效应的方法,拓展到GARCH模型上。
- LM:检验原模型是否显著,也可以拆分开,分别检验ARCH项和GARCH项是否显著,计算偏自相关系数,得到模型拟合优度,得出Q统计量。
- BP、LB:计算利用 和 的自相关系数,得出Q统计量。
说明
GAECH的特点是:可以认为是ARMA在波动率 上的应用。从过程推导,首先是 得到ARCH项,然后 得到GARCH项,按照ARMA的思想进行组合,就可以得到
所以先前在介绍ARCH模型,尽管 存在自相关,我们却把参数写成q,就是因为在GARCH中,ARCH部分实际上类似于ARMA的移动平均部分,GARCH项类似于自回归部分。
这样就做出了在有GARCH效应下波动率的准确的估计,进而提高预测序列值的精度。
在基础的GARCH上,还有其他衍生GARCH模型。
后续步骤
至此我们就完成了对模型的识别。接下来就是和计量经济学一样,展开参数估计、模型检验、模型优化、模型预测。
时间序列数据要重点结合实际,特别是要结合软件比如eviews、Stata的使用。
附录
| 阶数 | 公式 | 名称 | 意义 | 标准正态分布对应值 |
|---|---|---|---|---|
| 一阶中心矩 | 均值 | 说明数据分布的中心位置 | 0 | |
| 二阶中心矩 | 方差 | 描述数据的变化程度 | 1 | |
| 三阶中心矩 | 偏度 | 描述数据对称程度,大于零为右偏 | 0 | |
| 四阶中心矩 | 峰度 | 描述数据尾部厚度,峰度大于3或超额峰度大于0为厚尾 | 3, |
应用举例
有几篇写得较好,放在此处参考。
[波动性GARCH模型与波动率预测(代码+结果分析)_garch模型怎么看预测结果-CSDN博客](https://blog.csdn.net/celiaweiwei/article/details/133860867#:~:text=ARCH 模型是用于描述时间序列数据中异方差性(方差不恒定)的一种模型。 “ARCH”,代表 “Autoregressive Conditional Heteroskedasticity”,它的基本思想是将过去的误差项的平方作为当前时间点的方差模型的输入。)
下面只进行一些简单操作。
EXCEL简单分析
收集茅台近100个交易日的股价数据,在excel中简单计算并绘制相关图表。
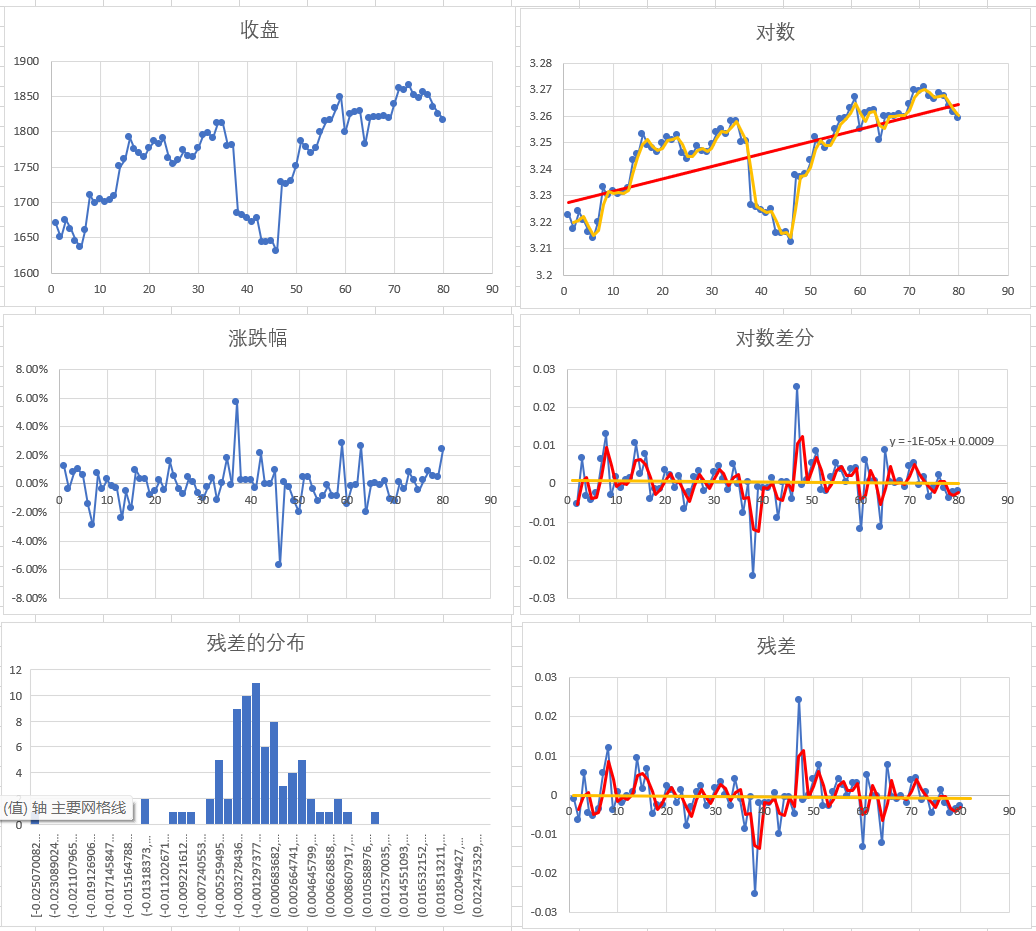
我们这里所使用的时间序列分析,是针对平稳序列展开的,最希望的理想状态就是被解释变量是一条水平线,也就是解释变量线性的组合是一条水平线,这个部分完全不变动。对于可能存在的波动,则用随机误差项来表示,所以相当于用一个确定的部分加上一个波动的部分,来模拟真实的情况。这个波动的部分,就是残差,所以数据所有和波动有关的研究,都是针对残差展开的。时间序列的分析,实际上就是把被解释变量分解为确定部分+随机波动部分,假如波动部分不随机,可以继续分解,直到得到完全随机的波动部分,这样就可以做出准确的预测。
生活中我们通常理解的平稳,例如一个稳定上升的数据,实际上不同于计量经济学里的平稳性,因为其均值是在变化的。实际上平稳的是这个上升序列的趋势,类似于物理中匀加速直线运动,平稳的不是速度,而是加速度。所以,对于均匀变化的序列,我们可以研究其变化的趋势,方法是计算变化率,在实际的运用里是用取对数差分的方法来近似的。
收集了81天茅台的日收盘价数据,直接绘图如图一。图二是对日收盘价取对数的结果,可以看到数据取对数后,整体范围区间缩小,异方差性减小。但是这个序列,仍然不接近我们希望看到的水平线,所以进行差分,得到收益率(数学上结果近似),可以看到“对数差分”这个序列就比较接近我们希望看到的样子了。针对研究其波动部分也就是残差的情况,绘制残差的分布,可以看到残差近似服从正态分布,残差序列自身也接近我们希望看到的样子。当然,我们仍然可以认为残差还可以有待改进,继续把残差分解为确定部分+波动部分进行预测。
MATLAb金融时间序列数据工具箱
在MATLAB中,可以实现很多的时间序列分析。
将数据导入进去,对原数据进行一阶差分、二阶差分、三阶差分,可以直观发现数据变得越来越平稳了。但是,并非越差分越好,多次差分之后数据很有可能反而近似于白噪声,难以找到规律进行预测。因此实际应用需要具体情况具体分析。

1 | logdata = log(data) |
遵循分析思路,首先识别数据的自相关类型。分别对原数据和对数数据、对数差分数据进行分析,计算其自相关系数、偏自相关系数,得到。





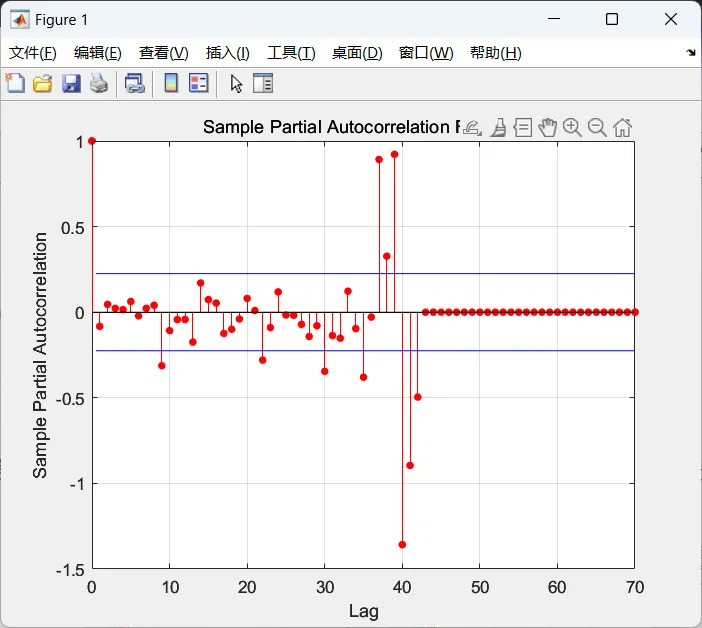
观察发现,原数据和对数数据ACF是8阶拖尾,PACF是1阶截尾,对数差分。
1 | ar(logdata, 2) |
白噪声
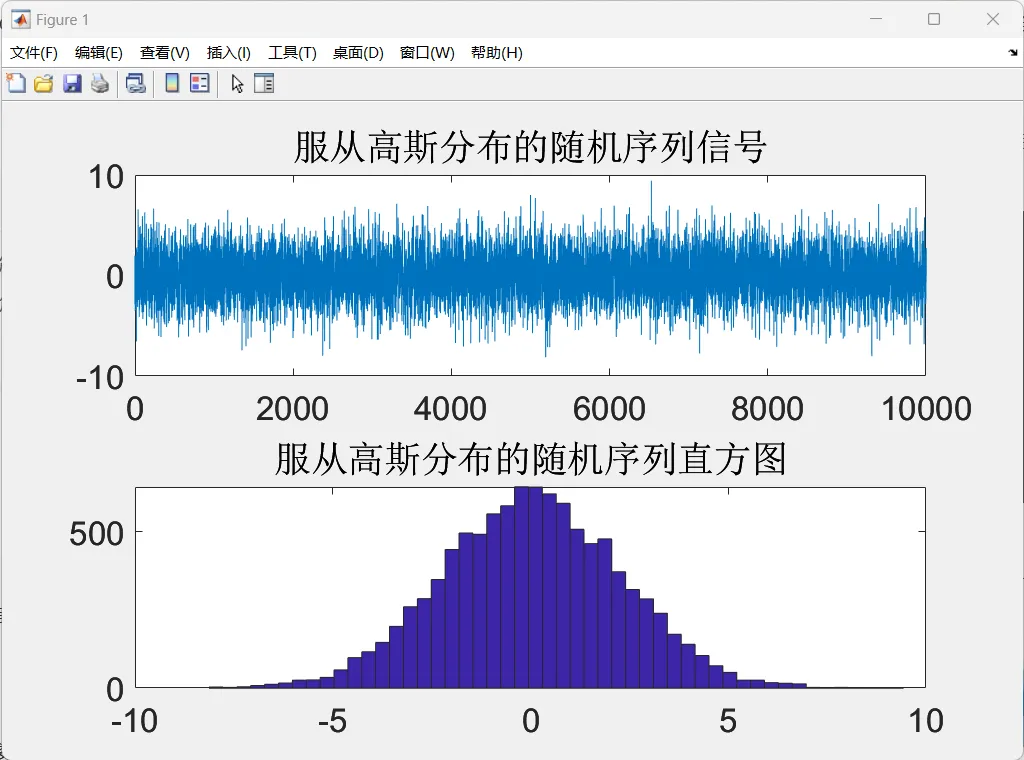
1 | ## 生成服从标准正态分布的白噪声 |
生成服从0均值方差为5的正态分布的白噪声(此处我使用MATLAB),可以看到其序列图、分布图如下。