目录
[toc]
模型的设定和估计
为什么用 多元线性回归 ?
因为一元线性回归的结果很难建立因果关系
引例:
income^=0.5+700∗schoolingyear
样本中可看出多一年教育年限收入就多700元,但我们不能简单得出 “增加一年教育年限,收入就可以提高700元” 的结论
多元回归 可以通过增加更多变量改善因果关系的建立
income^=0.5+700∗schoolingyear+500∗age
这个式子说明,年龄一样的人,教育年限多一年,收入平均多700元。如果我们通过控制所有特征(保证单一变量),得出的系数就可以认为是 建立起了教育年限和收入的因果关系
当然,由于我们不可能控制所有变量,多元回归分析只能说是改善而不是完全解决一元回归存在的问题
多元估计的一般形式
y=β0+β1∗x1+β2∗x2+⋯+βk∗xk+u
多元估计的矩阵形式
如果对被解释变量做n次观测,得到的n组观测值的线性关系,实际上可以写成矩阵形式:
Y1Y2⋮Ym=11⋮1X21X22⋮X2mX31X32⋮X3m⋯⋯⋯Xn1Xn2⋮Xnmβ1β2⋮βm+u1u2⋮um
多元总体线性回归函数的矩阵形式:
Y=Xβ+U
E(Y)=Xβ
类似的,我们可以把多元样本线性回归函数写成
Y=Xβ^+e
Y^=Xβ^
简单线性回归基本假定
- 假定一
零均值假定,即随机扰动项的条件期望等于0
- 假定二
同方差假定,即对于每一个给定的 Xi,随机扰动项的条件方差都等于 σ2
Var(ui∣Xi)=E[ui−E(ui∣Xi)]2=E(ui2)=σ2
- 假定三
无自相关假定,即各个扰动项的逐次值互不相关,也可以说他们的协方差等于零
Cov(ui,uk)=E[ui−E(ui)]E[uk−E(uk)]={σ2,0,i=ki=k(i,k=1,2,3,⋯n)
也就是说,
Var(U)=σ20⋮00σ2⋮0⋯⋯⋱⋯00⋮σ2=σ2In
Cov(ui,Xi)=E[ui−E(ui)]E[Xi−E(Xi)]=0
这一假定说明解释变量和扰动项是各自独立影响被解释变量的,从而得以分清各自的影响多少
- 假定五
正态性假定,即随机扰动项ui∼N(0,σ2)
- 假定六
无多重共线性。假设各解释变量的观测值线性无关,此时矩阵X满秩,也就是Rank(X)=k,方阵XTX满秩,从而方阵XTX可逆
最小二乘估计
OLS残差平方和最小
Min∑ei2={β^0,β^1,⋯,β^k}Mini=1∑n(Yi−β^0−β^1⋅Xi1−⋯−β^k⋅Xik)
需要
∂β^j∂(∑ei2)=0,(j=1,2,⋯,k)
即
−i=1∑n2⋅(Yi−β0^−β^1⋅Xi1−⋯−β^k⋅Xik)=0−i=1∑n2⋅Xi1⋅(Yi−β0^−β^1⋅Xi1−⋯−β^k⋅Xik)=0⋮−i=1∑n2⋅Xik⋅(Yi−β0^−β^1⋅Xi1−⋯−β^k⋅Xik)=0
括号中的正是残差ef,所以可以写出如下矩阵形式:
∑ei∑X2iei⋮∑Xkiei=XTe=00⋮0
对多元回归方程左乘XT
XTY=XTXβ^+XTe=XTXβ^
由无多重共线性可知,XTX的逆矩阵存在,可以得出
β^=(XTX)−1XTY
对于只有两个解释变量的回归模型,可以得出参数最小二乘估计式的代数表达式:
β^2=∑x2i2∑x3i2−(x2ix3i)2∑yix2i∑x3i2−∑yix3i∑x2ix3iβ^3=∑x2i2∑x3i2−(x2ix3i)2∑yix3i∑x2i2−∑yix2i∑x2ix3iβ^1=Yˉ−β^2Xˉ2−β^3Xˉ3
在软件中可以计算出来各个β
和一元回归一样,我们可以定义:
拟合值
Y^i=β^0+β^1⋅Xi1+⋯+β^k⋅Xik
残差
u^i=Yi−Y^i
残差,又称为剩余项
| 函数 |
名称 |
确定性 |
公式 |
| 总体回归函数 |
随机扰动项、误差项 |
确定 |
ui=Yi−E(Y∣Xi) |
| 样本回归函数 |
残差、剩余项 |
不确定(看抽样情况) |
Yi−Y^i=ei |
参数最小二乘估计的性质
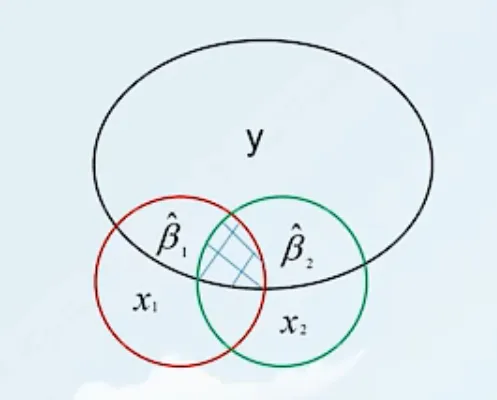
如何理解多元回归方程的系数?
Y^=β0^+β1^X1+β2^X2

- β1^ 是 X1 对 Y 的纯影响
- β2^ 是 X2 对 Y 的纯影响
多元回归有 k+1 个条件
根据线性代数,由矩阵可以得出
β^2=i=1∑nr^i12i=1∑nr^i1yi
Gauss-Markov定理
在六个基本假设成立的前提下,OLS估计量是 线性 无偏 最优估计量。
无偏性
- 系数线性的回归方程
- {(xi1,xi2,⋯,xik,yi):i=1,2,⋯n} 是随机样本
- 解释变量无多重共线(线性无关)
- E(u∣x1,x2,⋯,xk)=0,任何一个 xi 都不和 u 相关
定理
在假设一到四都满足的情况下,OLS估计量是无偏估计量,即
E(β^j∣x1,x2,⋯,xk)=βj,j=0,1,⋯,k
当抽样趋于无穷,估计值的均值越接近真实值
最小方差性
假设五(同方差性):
var(u∣x1,⋯,xk)=σ2
u在xi 的条件方差等于 σ2
如果假设一到五都成立,那么
var(β^j∣x1,⋯,xk)=SSTj(1−R2)σ2,j=1,2,⋯,k
SSTj=j=1∑n(xij−xˉj)2,j=1,2,⋯,k
其中,Rj2 是拿其他解释变量做回归得到的拟合优度
注意:
关于 var(β^0∣x1,⋯,xk) ,并没有给出相应公式,因为无法得到 1−R02 的数值。为了在多元回归里计算 var(β^0∣x1,⋯,xk) 需要使用矩阵相关知识
σ^2=n−k−1i=1∑nu^i2
在假设一到五成立的基础上,E(σ^2∣x1,x2,⋯,xk)=σ2
最小二乘估计的分布性质
E(βj^)Var(βj^)βj^=β=σ2cjj∼N[βj,σ2cjj]
其中,cjj 是矩阵 XTX 中的元素
随机扰动项方差的估计
基本方法和一元线性回归一致。
无偏估计
σ^2=n−k1∑ei2
则方差
Var(β^2)=σ^2cjj=(n−k1∑ei2)cjj
多元的假设检验和区间估计
假设检验
为说明多元线性回归线对样本观测值的拟合情况,我们可以通过拟合优度的判断,利用多重可决系数,考察被解释变量的总变差中由多个解释变量来做出解释的那部分变差的比重。在此基础上,还需要通过回归系数的显著性检验,得到回归系数的可靠估计量。
拟合优度
一元线性回归中我们使用了可决系数R2,来衡量估计的模型对观测值的拟合程度。在多元回归中,同样可以使用这样的方法。
由于是多元线性回归,存在多个解释变量。对被解释变量Y的变差分解如下:
变差自由度∑(Yi−Yˉ)2TSS(n−1)=∑(Yi−Yˉ)2+∑(Yi−Yˉ)2=ESS+RSS=(k−1)+(n−k)
和一元类似,
R2=TSSESS=1−TSSRSS
如果考虑自由度,对可决系数进行修正,可以得到:
Rˉ2=1−TSS/(n−1)RSS/(n−k)
显著性检验
在一元回归在我们使用过t检验,在此处同理可以使用t检验,检查回归参数的显著性。除此之外,我们还可以使用F检验,检查回归方程的显著性。
F检验
研究被解释变量和所有解释变量之间的线性关系是否显著,我们通常使用 F检验
F分布相关知识
X∼χ2(n1),Y∼χ2(n2)
Y/n2X/n1∼F(n1,n2)
F(n1,n2)1=F(n2,n1)
我们假设:
H0:β2=β2=⋯=β2=0H1:βj(j=2,3,⋯不全为零)这应该是一个单侧检验
在 H0 成立的基础上,构造统计量
F=RSS/(n−k)ESS/(k−1)∼F(k−1,n−k)
计算观测值,如果F>Fα(k−1,n−k),那么就拒绝原假设,说明回归方程显著,计入模型的解释变量对被解释变量有显著影响。反之没有显著影响。
一元线性回归中,解释变量只有一个,不存在整体检验的问题。此时进行F检验,和t检验是一样的。
F=RSS/(n−k)ESS/(2−1)=t2
同时可以发现,F统计量和可决系数R2有很大关系,区别在于前者考虑了自由度,后者没考虑自由度,可决系数指出了拟合程度,而F检验能告诉我们确定的界限
F=k−1n−k⋅1−R2R2
t检验
再多元回归中,我们同样可以对回归参数(系数)进行估计,对解释变量进行显著性检验。由于存在多个解释变量,因此我们对每个解释百年来进行显著性检验,可以得出当其他解释变量不变时,该解释变量是否对被解释变量有显著影响。
我们已经知道参数的性质:
βj^∼N[βj,σ2cjj]
因此,参数符合正态分布,构造Z统计量
Z=Var(β^j)β^j−βj∼N(0,1)
我们已知 Var(βj^)=σ2cjj ,但是由于不知道σ2,我们使用其无偏估计 σ^2=n−k1∑ei2 ,得到:
Var(β^2)=σ^2cjj=(n−k1∑ei2)cjj
构造t统计量
t=Var(β^j)β^j−βj=σ^cjjβ^j−βj=∼t(n−k)
假设检验:
H0:βj=0H0:βj=0(j=1,2,⋯,k)(j=1,2,⋯,k)
置信区间−tα/2(n−k)≤t≤tα/2(n−k)
如果∣t∗∣≤tα/2,说明影响显著。
区间估计
和一元基本一致,根据无偏估计写出构造的统计量,划分临界值得出置信区间。
预测
点预测
把各个解释变量的值带入估计的样本回归函数得出的就是点预测值。
平均值区间预测
实质是分析点预测值和平均值的关系,分析概率密度分布性质。记他们的偏差为
wf=Y^f−E(Yf)
E(wf)=0
可以知道偏差同样符合正态分布,有
wf∼N[0,σ2Xf(XTX)−1XfT]
用σ^2构造统计量,得到
t=SE(wf^)w^−E(wf)=σ^Xf(XTX)−1XfTY^f−E(Yf)
个别值区间预测
个别值偏差
ef=Y^f−Y^f
E(ef)=0
Var(ef)=σ2[1+Xf(XTX)−1XfT]
接下来
- 无偏估计
- 构造统计量符合t∼t(n−k)
- 根据置信水平,得出临界值,写出预测区间
Stata常用命令
与OLS有关的命令有两个:
regress
用OLS的方法来估计线性回归方程的系数
regress [被解释变量], [解释变量] (if条件语句)
例如:regress wage education experience,wage是 被解释变量,education 和experience 是两个 解释变量
例如:regress wage education experience if female==1加上性别为女的条件
predict
用来得到拟合值或残差,必须在回归命令regress之后使用
predict [新变量] 用于得到拟合值predict [新变量], residuals 用于得到残差
例如:
1
2
| regress wage education exprience
predict wage_hat
|
先对变量进行回归,然后拟合 wage^
1
2
| regress wage education exprience
predict resi, residuals
|
在新的变量里得到残差的估计值
Model对应的就是SSE,Residual对应SSR,Total对应SST
第一行wage是被解释变量,下面是解释变量。Coef. 是估计值,Std. Err 是估计量的标准差