计量经济学 | 1.计量经济学简介

计量经济学 | 1.计量经济学简介
Prong[toc]
- 计量经济学简介
简要介绍基本范畴
stata软件操作
- 线性回归模型
一元线性、多元线性
最小二乘法
线性回归模型基本假设
最小二乘法基本性质
- 统计推断和特殊应用
单系数检验、多系数检验
应用线性模型:虚拟变量
-
大样本性质
当样本量趋于无穷大,最小二乘量的性质 -
异方差和序列相关
放宽同方差假设、随机样本假设 -
内生性问题
解释变量和相关量被放宽后导致的后果
解决内生性问题
- 非线性回归模型
放宽线性假设
计量经济学简介
引例:选修经济学双学位真的能增加就业前景吗?
导致就业前景增加的变量不唯一,难以确定。为了回答此问题,需要:
- 明确研究问题
- 写出要估计的回归方程式
- 选择适当的数据集
- 使用统计软件,用数据估计回归方程式
- 分析并解释结果
计量经济模型中的变量
从经济活动的形态上,可以分为
- 流量
- 存量
从变量的因果关系,可以分为
- 解释变量:是变动的原因,常被称为“自变量” (independent variable),“回归元” (regressor)
- 被解释变量:研究的对象,是变动的结果,常被称为“应变量” (dependent variable),“回归子” (regressand)
根据变量的性质,可以分为
- 内生变量:模型求解的结果
- 外生变量:其数值由模型决定
外生变量可以影响内生变量,但内生变量不能反过来影响外生变量
参数的估计
由于模型中参数未知,我们需要样本信息进行估计。例如对于单一变量模型,最常用的是普通最小二乘法、极大似然估计法。对于联立方程组模型,常用二段最小二乘法、三段最小二乘法。
常用数据类型
- 横截面数据
不同被观测对象在同一时间内的观测值
- 时间序列数据
以时间为顺序观测的数据
需要严格按照时间排序
- 集合的横截面数据
- 观测时间不同
- 在不同的观测时间内,被观测对象不同
| 省份 | 年份 | 人口 | 人均GDP |
|---|---|---|---|
| 江西 | 1998 | ||
| 四川 | 1998 | ||
| 云南 | 2002 | ||
| 西藏 | 2002 |
- 面板数据
相同对象在不同时间内反复被观测得到的数据
| 省份 | 年份 | 人口 | 人均GDP |
|---|---|---|---|
| 江西 | 1998 | ||
| 江西 | 2002 | ||
| 云南 | 1998 | ||
| 云南 | 2002 |
- 虚拟变量数据
用于描述一些定性的、非此即彼类的事实,用0或1表示
STATA简介
界面
基本命令
- 打开数据集方式use
- 从工具栏直接打开
- 命令窗口输入命令use打开
1 | use "D:\Stata10\auto.dta" , clear |
- 保存数据集save
1 | save "D:\Stata10\example.dta" , replace |
相当于将打开的数据集保存在D:\Stata10下,同时重命名为example.dta。replace表示覆盖同一文件夹下同样名称的数据集
- 创建新变量
generate
1 | generate revenue=price*quantity |
相当于创建了名为revenue的新变量,且此变量等于已有变量price乘以quantity
- 删除变量或观察值drop
1 | drop revenue |
将先前的变量revenue从数据集中全部删除
1 | drop if revenue > 500 |
删除revenue大于500的观测值
- replace
1 | replace price = 2 |
- 计算基本统计量
1 | summarize price |
| Variable | Obs | Mean | Std.Dev. | Min | Max |
|---|---|---|---|---|---|
| price | 74 | 6165.257 | 2949.496 | 3291 | 15906 |
| 列出变量名 | 样本量(观测值数量) | 平均值 | 标准差 | 最大值 | 最小值 |
也可以列出多个变量的基本统计量
1 | summarize price quantity |
- 列出数据
- 方法一:只列出频率tab
1 | tab mpg |
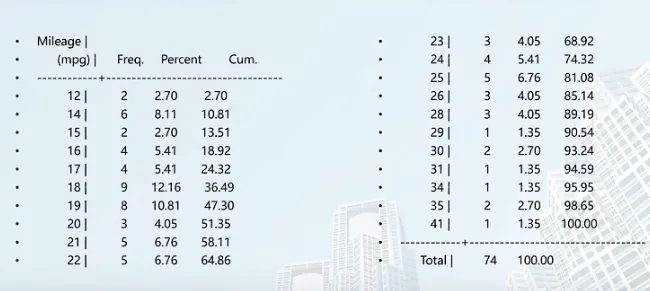
第一列是所有出现过的观测值,第二列是所有观测值出现的次数,第三列是每个观测值出现次数所占百分比,第四列是累加百分比
- 方法二:列出所有观测值list
1 | list mpg |
- 合并数据集
- 横向合并merge
不同数据集之间,至少要有一个相同的变量
1 | use "D:\Stata10\auto.dta" , clear |
- 纵向合并append
1 | use "D:\Stata10\auto.dta" , clear |
在这个例子中,我们合并了两个文件,合并后的数据集包括两个数据集中所有的变量;假如变量只在用来合并的第一个数据集集中出现,那么在合并后的数据集里,第二个数据集的该变量的值为缺失
- 查询帮助文件
- 已知语句,使用方法未知help
1 | help merge |
- 已知需求,语句未知search
1 | search ols |
.do文件
用来集合命令,同时运行多行程序,方便以后检查或重新使用,一般用此文件进行计量经济分析



喜欢这篇文章的人也看了
评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果