排序
k个东西排序,第k个有k种可能位置,第k-1个有k-1种,以此类推,排序可能性为
k!=k×(k−1)×(k−2)×⋯×1
组合(选取)
n个中选出r个对象,不考虑顺序,求出对象选取有多少种可能情况
Cnk=k!(n−k)!n!=k!Ank
排列(选取再排序)
Ank=(n−k)!n!=Cnk×k!
- 第一步,从n中选出k个,不考虑次序
- 第二步,对每个组合再进行排序,×k!
离散型
0~1分布
X∼B(x,p),
有两种结果,试验只做一次
二项分布的特殊情况
数学期望为E(X)=p,方差为D(X)=p(1−p)
几何分布
X∼G(p), Geometric
P{X=K}=(1−p)K−1p
第k次首次发生,此前k-1次均未发生
二项分布
X∼B(n,p), Binomial
P{X=K}=Cnkpk(1−p)n−k,k=0, 1, 2, 3...n
n次试验发生了k次
数学期望为E(X)=np,方差为D(X)=np(1−p)
最可能值
- (n+1)p不为整数,[(n+1)p]取整达到最大值
- (n+1)p不为整数,(n+1)p, (n+1)p−1达到最大值
具有可加性
近似求值
二项分布用泊松分布来近似
n比较大,p比较小,np适中
n≥100, np≤10
np=λ
二项分布用正态分布来近似 (de Moivre - Laplace)棣莫佛-拉普拉斯定理
n比较大,np也比较大
x→∞limP(np(1−p)Yn−np≤x)=Φ0(x)
- P(X≤k)
Y=np(1−p)X−np,P(X≤k)=P(Y≤np(1−p)k−np)=Φ(np(1−p)k−np)
- P(X=k)
P(X=k)=P(k−ϵ<X<k+ϵ), 再进行如上操作即可
泊松分布
X∼P(λ), Poisson
P{X=K}=K!λKe−λ,k=0,1,2,3...,λ>0
数学期望为E(X)=λ,方差为D(X)=λ。
超几何分布
X∼H(n,M,N), Hypergeometric
P{X=K}=CNnCN1kCN2n−k,N=N1+N2
可用于不放回抽样实验
当N很大,n很小,可视为放回抽样,此时可以使用二项分布计算
P{X=K}=CNnCN1kCN2n−k≈Cnkpk(1−p)n−k
近似计算
超几何分布N大 Nn小不放回视为放回二项分布n比较大,p比较小,np适中n≥100,np≤10,np=λ泊松分布
连续型
一般具有以下两个重要函数:
-
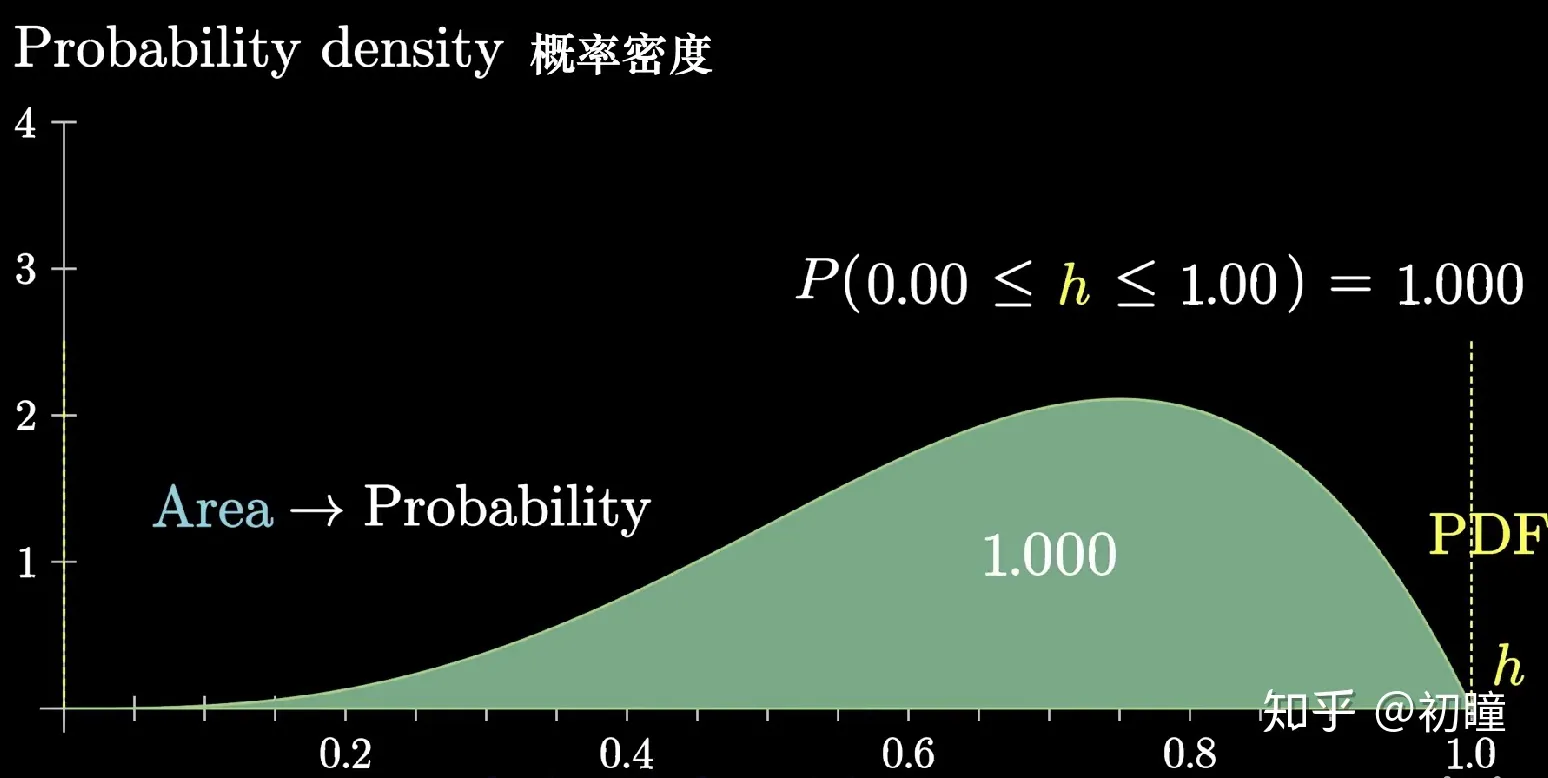
概率密度函数f(x)
- 概率密度函数是一个非负的函数,它表示随机变量取某个值或某个区间内的值的可能性大小。概率密度函数的面积就是相应的概率,即
P(a≤X≤b)=∫abf(x)dx
- 概率密度函数满足以下性质:
- f(x)≥0,对任意x。
- ∫−∞+∞f(x)dx=1。
- 如果P(X=x)=0,对任意x,则f(x)在x处不连续。
-
分布函数F(x)
- 分布函数是一个单调不减的函数,它表示随机变量小于等于某个值的概率。分布函数记为F(x)=P(X≤x)
- 分布函数满足以下性质:
- 0≤F(x)≤1,对任意x。
- F(−∞)=0,F(+∞)=1。
- 如果X是连续型随机变量,则F′(x)=f(x),对任意x。
均匀分布
X∼U[a,b], uniform
数学期望为E(X)=2(a+b),方差为D(X)=12(b−a)2
概率密度函数
f(x)=⎩⎨⎧b−a1,0a≤x≤b else
分布函数
F(x)=∫−∞xf(t)dt=⎩⎨⎧0b−ax−a,1x<aa≤x≤b b<x
指数分布
X∼Exp(λ), Exponential
数学期望为E(X)=1/λ,方差为D(X)=1/λ2。
常用于服务时间、寿命
概率密度函数
f(x)={λe−λx,0,x>0x≤0
分布函数
F(x)=P{X≤x}=∫−∞xf(t)dt={0,1−e−λx,x≤0x>0
正态分布
X∼N(μ,σ2), Normal
数学期望为E(X)=μ,方差为D(X)=σ2。
又称为高斯分布
一般
概率密度函数
ϕ(x)=2πσ1e−2σ2(x−μ)2,−∞≤x≤+∞
分布函数
Φ(x)=2πσ1∫−∞xe−2σ2(t−μ)2dt,−∞≤x≤+∞
标准
概率密度函数
ϕ(x)=2π1e−2x2,−∞≤x≤+∞
分布函数
Φ(x)=2π1∫−∞xe−2t2dt,−∞≤x≤+∞
数学期望为E(X)=0,方差为D(X)=1。
抽样分布
正态分布
和前文一致
卡方分布
Q∼χ2(v)
f(x)=22nΓ(2n)1x2n−1e−2x,x≥0
其中n是自由度,Γ是伽玛函数,数学期望为E(X)=n,方差为D(X)=2n
是n个相互独立的标准正态分布随机变量的平方和的分布
Σi−1nxi∼χ2(n),EX=n,DX=2n
由中心极限定理,n充分大时,T标准化后
2nT−n∼N(0,1),近似计算
t分布
X∼t(n)
若X∼N(0,1),Y∼χ2(n),X和Y独立
T=nYX∼t(n)
n越小,和正态分布差异越大
n≥30,和正态分布区别很小
上α分位数
P{T>ta(n)}=a
F分布