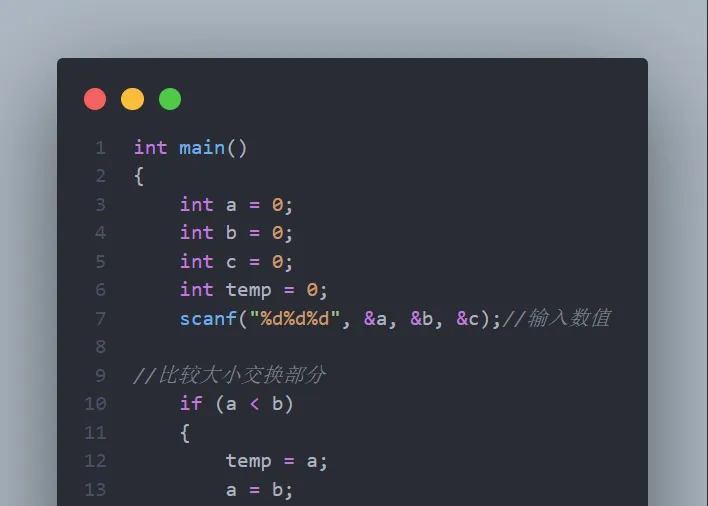
// 判断year这一年是不是闰年 boolis_leap_year(int year) { return year % 400 == 0 || year % 4 == 0 && year % 100; }
思路
四年一闰,百年不闰,四百年再闰。
打点滴问题
在医院打点滴(吊针)的时候,如果滴起来有规律,先是滴一滴,停一下;然后滴二滴,停一下;再滴三滴,停一下…,现在有一个问题:这瓶盐水一共有v毫升,每一滴是d毫升,每一滴的速度是一秒(假设最后一滴不到d毫升,则花费的时间也算一秒),停一下的时间也是一秒,这瓶水什么时候能滴完呢?(0 < d < v <6000)
signedmain() { int n; cin >> n; a[1][1] = 1; //计算杨辉三角 for (int i = 2; i <= n; i++) { for (int j = 1; j <= i; j++) { a[i][j] = a[i - 1][j - 1] + a[i - 1][j]; } } //输出前n行 for (int i = 1; i<= n;i++) { for (int j = 1; j<=i; j++) { cout << a[i][j] << " "; } cout << endl; } return0; }
判断素数
1 2 3 4 5 6 7 8 9 10 11 12
//判断是不是素数 boolis_prime(int x) { for (int i = 2; i <= x / i; i++) { // 防止溢出,使用了i<=x/i的写法 if (x % i == 0) { returnfalse; } } return x != 1; // 需要注意的就是1不是素数 }
斐波那契数列
1 2 3 4 5 6 7 8 9 10 11
intmain() { // 这里用前50项作为演示,实际上第50项就已经超出int的范围,需要用long long int a[55] = {0, 1, 1};//初始化数组前三项分别为0, 1, 1 for (int i = 3; i <= 50; i++) { a[i] = a[i - 2] + a[i - 1]; } // 此时a[i]代表斐波那契数列第i项的值 return0; }
voidwork() { // 定义一个函数work,不接受任何参数,也不返回任何值 int n; // 定义一个整数变量n,用来存储输入的个数 cin >> n; // 从标准输入读取一个整数,赋值给n vector<int> a(n); // 定义一个整数向量a,大小为n,用来存储输入的数据 // 如果是小数就把int改成double,是字符串就改成string for (int i = 0; i < n; i++) cin >> a[i]; // 用一个循环,从标准输入读取n个整数,依次存入向量a的每个位置 sort(a.begin(), a.end()); // 调用sort函数,对向量a从头到尾进行排序 // 此时a数组中即为从小到大排好序的数据 for (int i = 0; i < n; i++) cout << a[i] << " "; // 用一个循环,从向量a的每个位置依次取出数据,并用空格隔开打印到标准输出 // 输出数据,题目要求从大到小的顺序就倒着输出 }
最大公约数、最小公倍数
1 2 3 4 5 6 7 8 9 10
#include<bits/stdc++.h>//__gcd需要使用
intgcd(int a, int b) { return __gcd(a, b); // __gcd是一个内置函数(需要使用万能头文件),可以直接返回两个数的最大公约数,其中__就是两个下划线 } intlcm(int a, int b) { return a * b / __gcd(a, b); }
求 ab%p 的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// 计算a的b次方对p取模的结果,也就是(a^b) mod p。它使用了快速幂算法,可以在O(log b)的时间复杂度内完成计算。 // 定义一个函数ipow,接受三个整数参数a,b,p intipow(int a, int b, int p) { int res = 1; // 初始化结果为1 while (b) { // 当b不为0时,循环执行以下操作 if (b & 1) { res = res * a % p; } // 如果b的最低位是1,说明当前项需要乘到结果中,所以用res乘以a再对p取模 a = a * a % p; // 将a自乘再对p取模,相当于计算下一项的系数 b >>= 1; // 将b右移一位,相当于除以2,去掉最低位 } return res; // 返回最终结果 }
//最后出局的人 // 当n<10的8次方时使用 intjosephus(int n, int k) { int res = 0; for (int i = 1; i <= n; i++) res = (res + k) % i; return res; // 这里的编号是从0开始的,若题目中人的编号从1开始,则需要+1 } // 当n>10的8次方时使用 intjosephus(int n, int k) { if (n == 1) return0; if (k == 1) return n - 1; if (k > n) return (josephus(n - 1, k) + k) % n; int res = josephus(n - n / k, k); res -= n % k; if (res < 0) res += n; else res += res / (k - 1); return res; // 这里的编号是从0开始的,若题目中人的编号从1开始,则需要+1 }
判断回文串
1 2 3 4 5 6 7 8 9 10 11 12 13
// 使用string进行存储 boolis_leap(string s) { int lens = s.size() - 1; for (int i = 0; i < lens / 2; i++) { if (s[i] != s[lens - i]) { returnfalse; } } returntrue; }
数组排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
voidwork() { // 定义一个函数work,不接受任何参数,也不返回任何值 int n; // 定义一个整数变量n,用来存储输入的个数 cin >> n; // 从标准输入读取一个整数,赋值给n vector<int> a(n); // 定义一个整数向量a,大小为n,用来存储输入的数据 // 如果是小数就把int改成double,是字符串就改成string for (int i = 0; i < n; i++) { cin >> a[i]; } // 用一个循环,从标准输入读取n个整数,依次存入向量a的每个位置 sort(a.begin(), a.end()); // 调用sort函数,对向量a从头到尾进行排序 // 此时a数组中即为从小到大排好序的数据 for (int i = 0; i < n; i++) { cout << a[i] << " "; } // 用一个循环,从向量a的每个位置依次取出数据,并用空格隔开打印到标准输出 // 输出数据,题目要求从大到小的顺序就倒着输出 }
intmain() { int n; cin >> n; vector<int> a(n + 1), q(n + 1); for (int i = 0; i < n; i++) cin >> a[i]; int cur = 0; q[0] = -2e9; for (int i = 0; i < n; i++) { int l = 0, r = cur; while (l < r) { int mid = l + r + 1 >> 1; if (q[mid] < a[i]) l = mid; else r = mid - 1; } cur = max(cur, r + 1); q[r + 1] = a[i]; } cout << cur; return0; }
int a[N]; //用数组模拟哈希表,下标为当前出现的数,数组内部记录该数出现的次数 int n;
intmain() { cin >> n; for (int i = 0; i < n; i ++) { int x; cin >> x; a[x] ++; } int res = 0; //记录出现最大那个数 for (int i = 0; i < N; i ++) { if(a[i] > a[res]) res = i; } cout << res; return0; }